Алгоритмы - Разработка и применение - 2016 год
Направленные ациклические графы и топологическое упорядочение - Графы
Если ненаправленный граф не содержит циклов, то его структура чрезвычайно проста: каждая из его компонент связности представляет собой дерево. Однако направленный граф может и не иметь (направленных) циклов, обладая при этом довольно богатой структурой. Например, такие графы могут иметь большое количество ребер: если начать с множества узлов {1, 2, ..., n} и включать ребро (i, j) для всех i < j, то полученный направленный граф состоит из ![]() ребер, но не содержит циклов.
ребер, но не содержит циклов.
Если направленный граф не содержит циклов, он называется (вполне естественно) направленным ациклическим графом, или сокращенно DAG (Directed Acyclic Graph). Пример направленного ациклического графа изображен на рис. 3.7, а, хотя чтобы убедиться в том, что он не содержит направленных циклов, придется немного потрудиться.
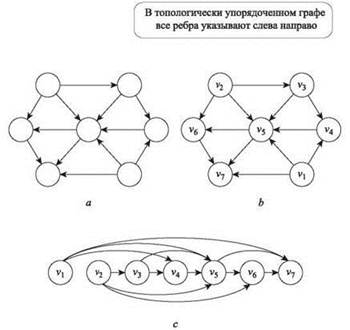
Рис. 3.7. а — направленный ациклический граф; b — тот же граф в топологическом порядке, обозначенном метками на каждом узле; c — другое представление того же графа, структурированное для выделения топологического порядка
Задача
Направленные ациклические графы (DAG) очень часто встречаются в теории обработки информации, потому что многие типы сетей зависимостей (см. раздел 3.1) ацикличны. Следовательно, DAG могут естественным образом использоваться для представления отношений предшествования или зависимостей. Допустим, имеется множество задач {1, 2, ..., n}, которые требуется выполнить; между задачами существуют зависимости — допустим, они указывают, что для пары i и j задача i должна быть выполнена до j. Скажем, задачи могут представлять учебные курсы, а некий курс можно пройти только после завершения необходимых вводных курсов. Или же задачи могут соответствовать последовательности вычислительных задач; задача j получает свои входные данные на выходе задачи i, поэтому задача i должна быть завершена до задачи j.
Для представления каждой задачи в таком взаимозависимом множестве задач создается узел, а требование о завершении i до j представляется направленным ребром (i, j). Чтобы отношения предшествования имели реальный смысл, полученный граф G должен быть направленным ациклическим графом, то есть DAG. В самом деле, если граф содержит цикл C, то никакие задачи из Cвыполнены быть не могут: так как каждая задача из C не может начаться до завершения другой задачи из C, ни одна из них не может быть выполнена первой.
Давайте немного разовьем это представление DAG как отношений предшествования. Для заданного множества задач с зависимостями возникает естественный вопрос о нахождении действительного порядка выполнения этих задач с соблюдением всех зависимостей, а именно: для направленного графа G топологическим упорядочением называется такое упорядочение его узлов v1, v2, ..., vn, при котором для каждого ребра (vi, vj) выполняется условие i < j. Иначе говоря, все ребра в этом упорядочении указывают “вперед”. Топологическое упорядочение задач описывает порядок их безопасного выполнения, то есть когда мы приходим к задаче vj, все задачи, которые ей должны предшествовать, уже были выполнены. На рис. 3.7, b узлы DAG из части (a) помечены в соответствии с их топологическим упорядочением; каждое ребро действительно ведет от узла с малым индексом к узлу с более высоким индексом.
Более того, топологическое упорядочение G может рассматриваться как прямое “свидетельство” отсутствия циклов в G.
(3.18) Если в графе G существует топологическое упорядочение, то граф G является DAG.
Доказательство. Действуя от обратного, предположим, что в графе G существует топологическое упорядочение v1, v2, ..., vn и цикл C. Пусть vi — узел C с наименьшим индексом, а vj — узел C, непосредственно предшествующий vi, следовательно, существует ребро (vj, vi). Но согласно нашему выбору i выполняется условие j > i, а это противоречит предположение о том, что v1, v2, ..., vn является топологическим упорядочением.
Гарантия ацикличности, предоставляемая топологическим упорядочением, может быть очень полезной даже на визуальном уровне. На рис. 3.7, c изображен тот же граф, что и на рис. 3.7, а и b, но с расположением узлов в соответствии с топологическим упорядочением. С первого взгляда видно, что граф (c) представляет собой DAG, потому что все ребра идут слева направо. ■
Вычисление топологического упорядочения
Основной вопрос, который нас интересует, по смыслу противоположен (3.18): существует ли топологическое упорядочение в каждом DAG, и если существует, как эффективно вычислить его? Универсальный метод получения ответа для любых DAG был бы очень полезен: он показал бы, что для произвольных отношений предшествования в множестве задач, не содержащем циклов, существует порядок выполнения этих задач, который может быть эффективно вычислен.
Проектирование и анализ алгоритма
На самом деле условие, обратное (3.18), выполняется, и для доказательства этого факта мы воспользуемся эффективным алгоритмом вычисления топологического упорядочения. Ключевым фактором станет определение отправной точки: с какого узла должно начинаться топологическое упорядочение? Такой узел v1 не должен иметь входящих ребер, поскольку любое входящее ребро нарушило бы определяющее свойство топологического упорядочения (все ребра должны указывать “вперед”). Следовательно, нужно доказать следующий факт:
(3.19) В каждом направленном ациклическом графе G существует узел v, не имеющий входящих ребер.
Доказательство. Пусть G — направленный граф, в котором каждый узел имеет по крайней мере одно входящее ребро. Мы покажем, как найти цикл в таком графе G; тем самым утверждение будет доказано. Выбираем любой узел v и начинаем переходить по ребрам в обратном направлении от v; так как v содержит как минимум одно входящее ребро (u, v), можно перейти к u; так как ребро u содержит как минимум одно входящее ребро (х, u), можно вернуться обратно к х; и т. д. Этот процесс может продолжаться бесконечно, так как каждый обнаруженный узел имеет входящее ребро. Но после n + 1 шагов какой-то узел w неизбежно будет посещен дважды. Если обозначить C серию узлов, встреченных между последовательными посещениями w, то Cочевидным образом образует цикл. ■
Существование такого узла v — все, что необходимо для построения топологического упорядочения G. Докажем посредством индукции, что каждый DAG имеет топологическое упорядочение. Это утверждение очевидно истинно для DAG с одним или двумя узлами. Теперь допустим, что оно истинно для DAG с количеством узлов до n. В DAG G с n + 1 узлом будет присутствовать узел v, не имеющий входящих ребер; его существование гарантировано по (3.19). Узел v ставится на первое место в топологическом упорядочении; такое размещение безопасно, поскольку все ребра из v указывают вперед. Теперь заметим, что граф G - {v} является DAG, поскольку удаление v не может привести к образованию циклов, не существовавших ранее. Кроме того, граф G - {v} содержит n узлов, что позволяет нам применить предположение индукции для получения топологического упорядочения G - {v}. Присоединим узлы G - {v} в этом порядке после v; в полученном упорядочении G все ребра будут указывать вперед, а следовательно, оно является топологическим упорядочением.
Итак, положение, обратное (3.18), успешно доказано.
(3.20) Если граф G является DAG, то в нем существует топологическое упорядочение.
Доказательство методом индукции содержит следующий алгоритм для вычисления топологического упорядочения G.

На рис. 3.8 изображена последовательность удалений узлов, происходящих при применении к графу на рис. 3.7. Закрашенные узлы на каждой итерации не имеют входящих ребер; здесь важно то, что, как гарантирует (3.19), при применении алгоритма к DAG всегда найдется хотя бы один такой узел, который может быть удален.
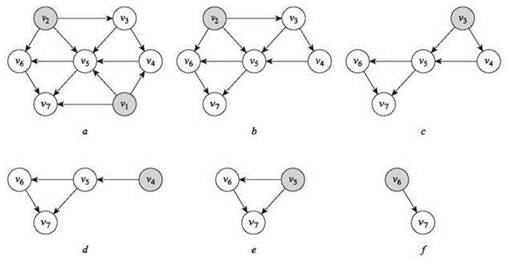
Рис. 3.8. Начиная с графа на рис. 3.7 узлы удаляются один за другим для добавления в топологическое упорядочение. Закрашенные узлы не имеют входящих ребер; следует заметить, что на каждой стадии выполнения алгоритма всегда найдется хотя бы один такой узел
Чтобы сформулировать оценку времени выполнения алгоритма, заметим, что нахождение узла v, не имеющего входящих ребер, и удаление его из G может выполняться за время O(n). Так как алгоритм выполняется за n итераций, общее время выполнения составит O(n2).
Результат не так уж плох; а для сильно разреженного графа G, содержащего Ө(n2) ребер, обеспечивается линейная зависимость от размера входных данных. Но если количество ребер mнамного меньше n2, хотелось бы чего-то большего. В таком случае время выполнения O(m + n) было бы значительным улучшением по сравнению с Ө(n2).
Оказывается, время выполнения O(m + n) может быть обеспечено тем же высокоуровневым алгоритмом — итеративным удалением узлов, не имеющих входящих ребер. Просто нужно повысить эффективность поиска таких узлов, а это можно сделать так.
Узел объявляется “активным”, если он еще не был удален алгоритмом, и мы будем явно хранить два вида данных:
(a) для каждого узла w — количество входящих ребер, ведущих к w от активных узлов; и
(b) множество S всех активных узлов G, не имеющих входящих ребер из других активных узлов.
В начале выполнения все узлы активны, поэтому данные (а) и (b) могут инициализироваться за один проход по узлам и ребрам. Тогда каждая итерация состоит из выбора узла v из множества Sи его удаления. После удаления v перебираются все узлы w, к которым существовали ребра из v, и количество активных входящих ребер, хранимое для каждого узла w, уменьшается на 1. Если в результате количество активных входящих ребер для w уменьшается до 0, то w добавляется в множество S. Продолжая таким образом, мы постоянно следим за узлами, пригодными для удаления, осуществляя постоянный объем работы на каждое ребро в ходе выполнения всего алгоритма.