Алгоритмы - Разработка и применение - 2016 год
Метод назначения цены: вершинное покрытие - Аппроксимирующие алгоритмы
Обратимся ко второму общему методу разработки аппроксимирующих алгоритмов: методу назначения цены. Для знакомства с этим методом будет рассмотрена версия задачи о вершинном покрытии. Как было показано в главе 8, задача о вершинном покрытии является частным случаем задачи покрытия множества, поэтому сначала мы рассмотрим возможность применения сведения при разработке аппроксимирующих алгоритмов. После этого мы разработаем алгоритм с улучшенными гарантиями аппроксимации по сравнению с обобщенной границей, полученной для задачи покрытия множества в предыдущем разделе.
Задача
Напомним, что вершинным покрытием в графе G = (V, E) называется такое множество S ⊆ V, что по крайней мере один конец каждого ребра принадлежит S. В версии задачи, которая рассматривается здесь, каждой вершине i ∈ V назначается вес wi ≥ 0, а вес множества вершин S обозначается ![]() Требуется найти вершинное покрытие S, для которого значение w(S) минимально. В стандартной версии задачи о вершинном покрытии все веса равны 1, и требуется принять решение о том, существует ли вершинное покрытие с весом не более k.
Требуется найти вершинное покрытие S, для которого значение w(S) минимально. В стандартной версии задачи о вершинном покрытии все веса равны 1, и требуется принять решение о том, существует ли вершинное покрытие с весом не более k.
Аппроксимация посредством сведения
Прежде чем переходить к разработке алгоритма, мы обсудим один интересный вопрос: задача о вершинном покрытии легко сводится к задаче покрытия множества, для которой мы только что рассмотрели аппроксимирующий алгоритм. Какие выводы можно сделать относительно аппроксимируемости вершинного покрытия? При рассмотрении этого вопроса проявляются некоторые неочевидные аспекты взаимодействия результатов аппроксимации со сведениями с полиномиальным временем.
Начнем с частного случая, в котором все веса равны 1, — иначе говоря, ищется вершинное покрытие минимального размера. Назовем этот случай невзвешенным. Вспомните, что для доказательства NР-полноты задачи покрытия множества использовалось сведение от невзвешенной версии задачи о вершинном покрытии с принятием решения, то есть
Вершинное покрытие ≤р Покрытие множества
Это сведение означает: “Если бы у нас был алгоритм с полиномиальным временем, решающий задачу покрытия множества, то мы могли бы использовать этот алгоритм для решения задачи о вершинном покрытии за полиномиальное время”. Теперь у нас есть алгоритм с полиномиальным временем, возвращающий приближенное решение для задачи покрытия множества. Означает ли это, что алгоритм может использоваться для формулировки аппроксимирующего алгоритма для задачи о вершинном покрытии?
(11.12) Аппроксимирующий алгоритм задачи покрытия множества может использоваться для получения Н(d)-аппроксимирующего алгоритма для взвешенной задачи о вершинном покрытии, где d — максимальная степень графа.
Доказательство. Оно базируется на сведении, которое демонстрировало, что Вершинное покрытие ≤р Покрытие множества; оно также распространяется на взвешенную версию. Рассмотрим экземпляр взвешенной задачи о вершинном покрытии, заданный графом G = (V, E). Экземпляр задачи покрытия множества определяется следующим образом: используемое множество U равно E. Для каждого узла i определяется множество Si, состоящее из всех ребер, инцидентных узлу i, и этому множеству назначается вес wi. Совокупности множеств, покрывающие U, точно соответствуют вершинным покрытиям. При этом максимальный размер любого множества Si точно совпадает с максимальной степенью d.
Следовательно, аппроксимирующий алгоритм для задачи покрытия множества может использоваться для нахождения вершинного покрытия, вес которого лежит в пределах множителя H(d) от минимума. ■
Эта Н(d)-аппроксимация достаточно хороша при малых d; но с ростом d она ухудшается, приближаясь к границе, логарифмической по количеству вершин. Позднее мы разработаем усиленный аппроксимирующий алгоритм, отличающийся от оптимума не более чем в 2 раза.
Но прежде чем заниматься 2-аппроксимирующим алгоритмом, мы должны отметить один факт: при использовании сведений для разработки аппроксимирующих алгоритмов необходимо действовать очень осторожно. В (11.12) такой подход сработал, но мы специально обосновали, почему он сработал; это вовсе не значит, что любое сведение с полиномиальным временем приводит к аналогичному выводу для аппроксимирующего алгоритма.
Рассмотрим поучительный пример: мы использовали задачу о независимом множестве, чтобы доказать NР-полноту задачи о вершинном покрытии. А именно, мы доказали
Независимое множество ≤р Вершинное покрытие
Это означает: “Если бы у нас был алгоритм с полиномиальным временем, решающий задачу о вершинном покрытии, то мы могли бы использовать этот алгоритм для решения задачи о независимом множестве за полиномиальное время”. Сможем ли мы использовать аппроксимирующий алгоритм для вершинного покрытия с минимальным размером для разработки соизмеримо хорошего аппроксимирующего алгоритма для независимого множества с максимальным размером?
Ответ — нет. Вспомните, что множество I вершин называется независимым в том, и только в том случае, если его дополнение S = V - 1 является вершинным покрытием. Для заданного вершинного покрытия S* с минимальным размером мы получим независимое множество с максимальным размером, вычисляя дополнение I* = V - S. Теперь предположим, что мы используем аппроксимирующий алгоритм задачи о вершинном покрытии для получения приближенного минимального вершинного покрытия S. Дополнение I = V - S действительно является независимым множеством — здесь проблем нет. Проблемы появляются тогда, когда мы пытаемся определить коэффициент аппроксимации для задачи о независимом множестве; I может быть очень далеко от оптимума. Предположим, например, что оптимальное вершинное покрытие S* и оптимальное независимое множество I* оба имеют размер |V|/2. Если выполнить 2-аппроксимирующий алгоритм для задачи о вершинном покрытии, вполне возможно, что мы вернемся к множеству S = V. Но в этом случае “приближенное максимальное независимое множество” I = V - S не содержит элементов.
Разработка алгоритма: метод назначения цены
Хотя (11.12) предоставляет аппроксимирующий алгоритм с доказуемыми гарантиями, это не лучший вариант. Следующее описание хорошо демонстрирует применение метода назначения цены при разработке аппроксимирующих алгоритмов.
Применение метода назначения цены для минимизации стоимости
Метод назначения цены (также называемый прямо-двойственным методом) основан на экономических представлениях. Для задачи о вершинном покрытии веса мы будем рассматривать веса узлов как стоимости, а каждое ребро — как необходимость оплаты его “доли” в стоимости найденного вершинного покрытия. На самом деле мы уже видели пример подобного анализа в жадном алгоритме для покрытия множества из раздела 11.3; он тоже может рассматриваться как алгоритм назначения цены. Жадный алгоритм покрытия множества определял значения cs — стоимости, оплачиваемые алгоритмом за покрытие элемента s. Значение cs может рассматриваться как “доля” элементам в стоимости. Утверждение (11.9) показывает, что модель долевого участия csочень естественна, так как сумма долей ![]() равна стоимости покрытия множества С, возвращаемой алгоритмом,
равна стоимости покрытия множества С, возвращаемой алгоритмом, ![]() Ключом к доказательству того, что алгоритм является H(d*)-аппроксимирующим, было некоторое приближенное свойство “справедливости” долей стоимости: (11.10) показывает, что оплата за элементы множества Sk превосходит стоимость покрытия их множеством Sk не более чем в H(|Sk|) раз.
Ключом к доказательству того, что алгоритм является H(d*)-аппроксимирующим, было некоторое приближенное свойство “справедливости” долей стоимости: (11.10) показывает, что оплата за элементы множества Sk превосходит стоимость покрытия их множеством Sk не более чем в H(|Sk|) раз.
В этом разделе мы воспользуемся методом назначения цены на другом примере — на примере задачи о вершинном покрытии. И снова вес wi вершины i будет рассматриваться как стоимость использования i в покрытии. Каждое ребро e будет рассматриваться как отдельный “агент”, желающий “заплатить” что-то покрывающему его узлу. Алгоритм будет не только находить вершинное покрытие S, но и определять цены pe ≥ 0 для каждого ребра e ∈ E, так что если каждое ребро e ∈ E платит цену pe, в сумме это приблизительно покроет стоимость S. Цены peявляются аналогами cs из алгоритма о покрытии множества.
Интерпретация ребер как “агентов” предполагает некоторые естественные правила “справедливости” цен, аналогичные свойству, доказанному (11.10). Прежде всего, выбор вершины iпокрывает все ребра, инцидентные i, поэтому будет “несправедливо” взимать за эти инцидентные ребра оплату, в сумме превосходящую стоимость вершины i. Цены pe будут называться справедливыми, если для каждой вершины i за ребра, смежные с i, не приходится платить больше стоимости вершины: ![]() Обратите внимание: свойство, доказанное (11.10) для задачи покрытия множества, является приближенным условием справедливости, тогда как в алгоритме вершинного покрытия будет использоваться точная концепция справедливости, определенная здесь. Полезная особенность справедливых цен заключается в том, что они всегда предоставляют нижнюю границу стоимости любого решения.
Обратите внимание: свойство, доказанное (11.10) для задачи покрытия множества, является приближенным условием справедливости, тогда как в алгоритме вершинного покрытия будет использоваться точная концепция справедливости, определенная здесь. Полезная особенность справедливых цен заключается в том, что они всегда предоставляют нижнюю границу стоимости любого решения.
(11.13) Для каждого вершинного покрытия S* и любых неотрицательных и справедливых цен ре выполняется ![]()
Доказательство. Рассмотрим вершинное покрытие S*. По определению справедливости имеем ![]() для всех узлов i ∈ S*. Суммируя эти неравенства по всем узлам S*, получаем
для всех узлов i ∈ S*. Суммируя эти неравенства по всем узлам S*, получаем
![]()
Теперь выражение в левой части представляет собой сумму слагаемых, каждое из которых представляет собой некоторую цену ребра pe. Поскольку S* является вершинным покрытием, каждое ребро e вносит как минимум одно слагаемое pe в левую часть. Оно может внести в сумму более одного экземпляра pe, потому что может покрываться S* с обоих концов; но цены неотрицательные, поэтому сумма в левой части по крайней мере не меньше суммы всех цен pe. А значит,
![]()
Объединяя с предыдущим неравенством, получаем:
![]()
как и требовалось. ■
Алгоритм
Целью аппроксимирующего алгоритма является поиск вершинного покрытия одновременно с назначением цен. Алгоритм можно рассматривать как жадный в отношении того, как он назначает цены. Затем цены используются для управления выбором узлов вершинного покрытия.
Узел i называется насыщенным (или “оплаченным”), если ![]()

Для примера рассмотрим выполнение алгоритма для экземпляра на рис. 11.8. Изначально плотных узлов нет; алгоритм решает выбрать ребро (a, b). Он может поднять цену, оплачиваемую (a, b), до 3; в этот момент узел b становится плотным и повышение останавливается. Затем алгоритм выбирает ребро (a, d). Оно может поднять цену только на 1, так как в этот момент узел становится насыщенным (так как вес узла a равен 4 и он уже инцидентен ребру с оплатой 3). Наконец, алгоритм выбирает ребро (c, d). Он может поднять цену, оплачиваемую (c, d), на 2, когда узел d становится насыщенным. В возникшей ситуации у каждого ребра имеется хотя бы один насыщенный конец, поэтому алгоритм завершается. Насыщенными являются узлы a, b и d; это и есть полученное вершинное покрытие. (Обратите внимание: это вершинное покрытие не минимально; для получения минимального покрытия следовало бы выбрать a и c.)
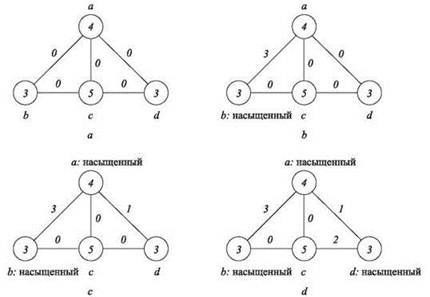
Рис. 11.8. Части (a)-(d) представляют шаги выполнения алгоритма назначения цены в экземпляре взвешенной задачи о вершинном покрытии. Числа в узлах обозначают веса; числа у ребер обозначают цены, выплачиваемые в ходе выполнения алгоритма
Анализ алгоритма
На первый взгляд может показаться, что вершинное покрытие S полностью оплачивается ценами: все узлы в S насыщенны, а следовательно, ребра, прилегающие к узлу i в S, могут оплачивать стоимость i. Но дело в том, что ребро e может прилегать к более чем одному узлу вершинного покрытия (если оба конца e принадлежат покрытию), и возможно, e придется “платить” более чем за один узел. Например, так обстоит дело с ребрами (a, b) и (a, d) в конце выполнения алгоритма на рис. 11.8.
Однако заметьте, что если взять ребра, для которых оба конца принадлежат вершинному покрытию и мы взимаем их цену дважды, то мы в точности оплачиваем вершинное покрытие. (В примере стоимость вершинного покрытия складывается из стоимости узлов a, b и d, которая равна 10. Эта стоимость складывается из двукратной оплаты (a, b) и (a, d) и однократной оплаты (c, d).) Действительно, для некоторых ребер это несправедливо, но величина несправедливости может быть ограничена: каждое ребро оплачивается не более двух раз (по одному для каждого конца).
Формализуем этот аргумент:
(11.14) Для множества S и цен р, возвращаемых алгоритмом, выполняется неравенство ![]()
Доказательство. Все узлы в S являются насыщенными, поэтому ![]() для всех i ∈ S. Суммируя по всем узлам в S, получаем
для всех i ∈ S. Суммируя по всем узлам в S, получаем
![]()
Ребро e = (i, j) может входить в сумму в правой части не более двух раз (если i и j входят в S), поэтому мы получаем
![]()
как и было заявлено. ■
Наконец, этот множитель 2 переходит в утверждение, дающее гарантии аппроксимации.
(11.15) Множество S, возвращаемое алгоритмом, является вершинным покрытием, а его стоимость не более чем вдвое превышает стоимость минимального вершинного покрытия.
Доказательство. Сначала докажем, что S действительно является вершинным покрытием. Предположим от обратного, что S не покрывает ребро e = (i, j). Из этого следует, что ни i, ни jненасыщенны, а это противоречит тому факту, что цикл Пока в алгоритме завершился.
Чтобы получить заявленную границу аппроксимации, достаточно объединить (11.14) с (11.13). Пусть р — цены, заданные алгоритмом, a S* — оптимальное вершинное покрытие. Согласно (11.14), имеем ![]() а по (11.13) -
а по (11.13) - ![]()
Другими словами, сумма цен ребер является нижней границей для веса любого вершинного покрытия, а удвоенная сумма цен ребер является верхней границей веса нашего вершинного покрытия:
![]()