Алгоритмы - Разработка и применение - 2016 год
Упражнения с решениями - Урок 13 - Рандомизированные алгоритмы
Упражнение с решением 1
Допустим, в здании установлено несколько компактных маломощных устройств, способных обмениваться данными на небольших расстояниях по беспроводной связи. Для простоты будем считать, что радиус действия каждого устройства достаточен для взаимодействия с d другими устройствами. Тогда систему беспроводных подключений между устройствами можно смоделировать ненаправленным графом G = (V, E), в котором каждый узел инцидентен ровно dребрам.
Некоторые узлы требуется оснастить более сильным передатчиком, который может использоваться для отправки данных на базовую станцию. Установка такого передатчика на всех узлах гарантирует, что данные смогут передаваться всеми узлами, но того же эффекта можно достичь и при меньшем количестве передатчиков. Допустим, нам удастся найти подмножество S узлов, обладающих тем свойством, что каждый узел в V-S имеет смежный узел в S. Такое множество будет называться доминирующим, потому что оно “доминирует” над всеми остальными узлами в графе. Если установить передатчики только на узлах доминирующего множества, данные все равно можно будет получать со всех узлов: любой узел u ∉ S cможет выбрать соседа v ∈ S и отправить свои данные v, чтобы узел v передал данные базовой станции.
Вопрос в том, как найти доминирующее множество S с минимально возможным размером, потому что это сведет к минимуму количество необходимых передатчиков. Эта задача является NР-сложной; доказательство ее составляет суть упражнения 29 в главе 8. (Также обратите внимание на различия между доминирующими множествами и вершинными покрытиями: в доминирующем множестве может присутствовать ребро (u, v), в котором ни u, ни v не входят в множество S — при условии, что у u и v есть соседи в S. Таким образом, например, граф из трех узлов, соединенных ребрами, имеет доминирующее множество с размером 1, но ни одного вершинного покрытия с размером 1.)
Несмотря на NР-полноту задачи, в таких ситуациях важно найти доминирующее множество как можно меньшего размера, даже если оно не оптимально. Оказывается, простая стратегия рандомизации может быть достаточно эффективной. Вспомните, что в графе G каждый узел инцидентен ровно ребрам. Очевидно, что любое доминирующее множество должно иметь размер не менее ![]() потому что каждый узел, включенный в доминирующее множество, может “обслуживать” только себя самого и d своих соседей. Требуется показать, что случайный выбор узлов действительно подведет нас достаточно близко к этой простой нижней границе.
потому что каждый узел, включенный в доминирующее множество, может “обслуживать” только себя самого и d своих соседей. Требуется показать, что случайный выбор узлов действительно подведет нас достаточно близко к этой простой нижней границе.
Покажите, что для некоторой константы с множество из ![]() узлов, случайно и равномерно выбираемых из G, с высокой вероятностью образует доминирующее множество. (Иначе говоря, это полностью случайное множество с большой вероятностью образует доминирующее множество, которое всего в O(log n) раз больше простой нижней границы
узлов, случайно и равномерно выбираемых из G, с высокой вероятностью образует доминирующее множество. (Иначе говоря, это полностью случайное множество с большой вероятностью образует доминирующее множество, которое всего в O(log n) раз больше простой нижней границы ![]()
Решение
Пусть ![]() где константа c будет выбрана позднее, когда мы получим более
где константа c будет выбрана позднее, когда мы получим более
ясное представление о происходящем. Обозначим E событие “случайно выбранные k узлов образуют доминирующее множество для G”. Чтобы упростить анализ, мы рассмотрим модель, в которой узлы выбираются по одному и один узел может встречаться дважды (если он будет выбран дважды в результате серии случайных решений).
Теперь нужно показать, что при достаточно больших с (а следовательно, и k) Рr[E] близко к 1. Но Е — исключительно сложное событие, поэтому для начала мы разобьем его на более простые события, вероятности которых проще анализировать.
Начнем с определения некоторых терминов. Узел w доминирует над узлом v, если w является соседом v, или w = v. Множество S доминирует над узлом v, если некоторый элемент S доминирует над v. (Эти определения позволяют сказать, что доминирующее множество — просто множество узлов, доминирующее над каждым узлом в графе.) Обозначим D[v, t] событие “выбранный t-й случайный узел доминирует над узлом v”. Вероятность этого события вычисляется очень просто: из n узлов графа должен быть выбран узел v или один из d его соседей, поэтому
![]()
Пусть Dv — событие “случайное множество состоящее из всех k выбранных узлов, доминирует над v. Тогда
![]()
Как уже говорилось, для независимых событий проще работать с пересечениями (где вероятности можно просто перемножить), чем с объединениями. Итак, вместо того, чтобы анализировать Δv, мы рассмотрим дополняющее “событие неудачи” ![]() “ни один узел в случайном множестве не доминирует над v”. Чтобы ни один узел не доминировал над v, ни один вариант выбора не должен доминировать, поэтому мы имеем
“ни один узел в случайном множестве не доминирует над v”. Чтобы ни один узел не доминировал над v, ни один вариант выбора не должен доминировать, поэтому мы имеем
![]()
Так как события ![]() независимы, вероятность в правой части можно вычислить умножением всех отдельных вероятностей; следовательно
независимы, вероятность в правой части можно вычислить умножением всех отдельных вероятностей; следовательно
![]()
Так как ![]() последнее выражение можно записать в виде
последнее выражение можно записать в виде
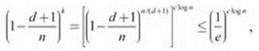
где неравенство следует из утверждения (13.1), приведенного ранее в этой главе.
Мы еще не указали основание для логарифма, используемого для определения k, но похоже, основание e будет хорошим вариантом. С ним последнее выражение упрощается до
![]()
Работа почти закончена. Мы показали, что для каждого узла v вероятность того, что случайное множество не будет доминирующим, не превышает значение n-c, которое можно сократить до очень малой величины, сделав c достаточно большим. Теперь вспомним исходное событие Е (случайное множество является доминирующим). Оно не происходит в том, и только в том случае, если не происходит одно из событий Dv, так что ![]() Следовательно, из границы объединения (13.2) получаем
Следовательно, из границы объединения (13.2) получаем
![]()
Если просто выбрать с = 2, вероятность становится равной 1/n, что намного меньше 1. Таким образом, с высокой вероятностью событие Е выполняется, а случайный выбор узлов действительно является доминирующим множеством.
Интересно заметить, что вероятность успеха как функция k проявляет поведение, очень сходное с тем, которое мы видели в примере с разрешением конфликтов из раздела 13.1. Выбора k = Ө(n/k) достаточно для того, чтобы гарантировать доминирование над каждым отдельным узлом с постоянной вероятностью. Впрочем, для получения полезного результата из границы объединения этого недостаточно. Увеличение k с логарифмическим множителем позволило повысить вероятность доминирования над каждым узлом до величины, очень близкой к 1, когда можно воспользоваться границей объединения.
Упражнение с решением 2
Предположим, имеется множество из n переменных x1, x2, ..., xn, принимающих значения из множества {0, 1}. Также имеется множество из k равенств; r-е равенство имеет форму
![]()
для некоторого выбора двух разных переменных xi, хj и для некоторого значения br, равного либо 0, либо 1.
Таким образом, каждое равенство определяет, четна или нечетна сумма двух переменных.
Рассмотрим задачу нахождения присваивания значений переменным, которая максимизирует количество выполняемых равенств (то есть тех, для которых условие действительно истинно). Задача является NР-сложной, хотя доказывать это не нужно.
Предположим, даны следующие равенства:
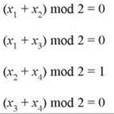
для четырех переменных x1, ..., x4. Тогда возможно показать, что никакое присваивание значений переменным не выполняет все равенства одновременно, но присваивание всем переменным 0 выполняет три равенства из четырех.
(a) Пусть с* — максимально возможное количество равенств, которые могут быть выполнены присваиванием значений переменным. Предложите алгоритм с полиномиальным временем для получения присваивания, выполняющего по крайней мере 1/2c* равенств. При желании алгоритм можно рандомизировать; в этом случае ожидаемое количество выполняемых равенств должно быть не менее 1/2с*. В любом случае следует доказать, что алгоритм обеспечивает заявленные гарантии эффективности.
(b) Допустим, ограничение, согласно которому каждое равенство должно содержать ровно две переменные, отменяется; другими словами, теперь каждое равенство просто указывает, что остаток от деления суммы произвольного подмножества переменных на 2 равен заданному значению br.
И снова обозначим с* максимально возможное количество равенств, которые могут быть выполнены присваиванием значений переменным. Предложите алгоритм с полиномиальным временем для получения присваивания, выполняющего по крайней мере 1/2c* равенств. (Как и в предыдущем пункте, алгоритм может быть рандомизированным.) Если вы полагаете, что ваш алгоритм из пункта (a) тоже предоставляет такую гарантию, укажите это и обоснуйте, приведя доказательство гарантий эффективности для более общего случая.
Решение
Вспомним основной вывод простого рандомизированного алгоритма для задачи MAX 3-SAT, приведенный ранее в этой главе: в задаче на выполнение условий случайное присваивание значений переменным может быть неожиданно эффективным способом выполнения постоянной части всех ограничений.
Попробуем применить этот принцип в текущей задаче, начиная с части (a). Рассмотрим алгоритм, который присваивает всем переменным случайные значения с равномерным распределением. Насколько хорошо работает это случайное присваивание в ожидании?
Как обычно, для получения ответа будет использована линейность ожидания: возьмем X — случайную переменную, обозначающую количество выполненных равенств, и разобьем ее на сумму более простых случайных переменных.
Пусть для некоторого r в диапазоне от 1 до kr-е равенство имеет вид
![]()
Случайная переменная Xr равна 1, если это равенство выполняется, и 0 в противном случае. E[Xr] — вероятность того, что равенство r выполняется. Из четырех возможных вариантов присваивания равенству i в двух левая часть дает результат 0 mod 2 (хi = хj = 0 и хi = хj = 1), а в двух других 1 mod 2 (хi = 0; хj = 1 и хi = i; хj = 0). Следовательно, Е[Xr] = 2/4 = 1/2.
Из линейности ожидания имеем ![]() Так как максимальное количество выполняемых равенств с* не должно превышать k, в ожидании выполняются не менее с*/2 равенств. Следовательно, как и в случае задачи MAX 3-SAT, при простом случайном присваивании выполняется постоянная часть всех ограничений.
Так как максимальное количество выполняемых равенств с* не должно превышать k, в ожидании выполняются не менее с*/2 равенств. Следовательно, как и в случае задачи MAX 3-SAT, при простом случайном присваивании выполняется постоянная часть всех ограничений.
В части (b) попробуем рискнуть и воспользоваться тем же алгоритмом. И снова пусть Xr — случайная переменная, которая равна 1, если r-е уравнение выполняется, и 0 в противном случае; X — общее количество выполненных равенств и с* — оптимум.
Хотелось бы заявить, что Е[Xr] = 1/2, как и прежде, даже при произвольном количестве переменных в r-м равенстве; другими словами, вероятность того, что равенству будет присвоено правильное значение mod 2, составляет ровно 1/2. Просто записать все случаи, как это было сделано для равенств с двумя переменными, не удастся, поэтому будет использоваться альтернативное обоснование.
Доказать, что Е[Xr] = 1/2, можно двумя естественными способами. В первом используется прием, встречавшийся в доказательстве (13.25) из раздела 13.6 для хеширования: мы рассматриваем присваивание произвольных значений всем переменным, кроме последней, а затем присваиваем случайное значение последней переменной х. Независимо от того, как были присвоены значения других переменных, присвоить значение x можно двумя способами; нетрудно проверить, что с одним из них равенство выполняется, а с другим нет. Таким образом, независимо от присваивания значений переменным, отличным от x, вероятность присваивания х с выполнением равенства составляет ровно 1/2. Итак, вероятность того, что равенство будет выполнено при случайном присваивании, равна 1/2.
(Как и в доказательстве (13.25), это обоснование можно записать в контексте условных вероятностей. Если Е — событие выполнения равенства, а Fb - событие присваивания переменным, отличным от х, последовательности значений b, то Рr[E | Fb] = 1/2 для всех b, а следовательно, ![]()
В другом доказательстве просто подсчитывается количество способов, которыми в r-м равенстве может быть достигнута четная или нечетная сумма. Если удастся показать, что эти два числа равны, то вероятность того, что случайное присваивание выполнит r-е равенство, совпадает с вероятностью получения правильной четности/нечетности суммы, которая равна 1/2.
Собственно, на высоком уровне это доказательство практически эквивалентно предыдущему, не считая того, что базовую счетную задачу удается сформулировать явно. Предположим, r-е равенство состоит из t слагаемых; тогда существуют 2t возможных вариантов присваивания переменным в этом равенстве. Утверждается, что с 2t-1 присваиваний сумма будет четной, а с другими 2t-1 — нечетной; это покажет, что Е[Xr] = 1/2. Мы докажем это утверждение индукцией по t. Для t = 1 используются всего два присваивания, по одному для каждого варианта четности; для t = 2 доказательство уже приводилось выше для всех 22 = 4 возможных присваиваний. Теперь предположим, что утверждение выполняется для произвольного значения t - 1. Тогда существуют ровно 2t-1 способов получить четную сумму с t переменными:
♦ 2t-2 способов получения четной суммы для первых t - 1 переменных (по индукции) c приваиванием 0 t-й переменной, плюс
♦ 2t-2 способов получения нечетной суммы для первых t - 1 переменных (по индукции) c приваиванием 1 t-й переменной.
Остальные 2t-1 присваиваний дают нечетную сумму, и на этом шаг индукции завершается.
Зная, что Е[Xr] = 1/2, мы можем завершить доказательство по аналогии с частью (а): из линейности ожидания следует ![]()
Упражнения
1. Формулировка задачи 3-раскраски предполагает ответ “да/нет”, но задачу также можно переформулировать в виде оптимизационной задачи.
Допустим, имеется граф G = (V, E), каждый узел которого должен быть окрашен в один из трех цветов, даже если не удастся назначить разные цвета каждой паре смежных узлов. Ребро (u, v) будет называться реализованным, если u и v назначены разные цвета.
Рассмотрим 3-раскраску, максимизирующую количество реализованных ребер, и обозначим это количество с*. Предложите алгоритм с полиномиальным временем, который дает 3-раскраску, реализующую не менее 2/3c* ребер. При желании алгоритм можно рандомизировать; в этом случае ожидаемое количество реализуемых ребер должно быть не менее 2/3c*.
2. Рассмотрим округ, в котором проживают 100 000 избирателей. В списке для голосования всего два кандидата: от демократической партии (D) и от республиканской партии (R). Так уж сложилось, что округ населен в основном сторонниками демократов, так что 80 000 избирателей идут на выборы с намерением голосовать за D, а 20 000 избирателей собираются голосовать за R. Тем не менее правила голосования достаточно сложны, поэтому каждый избиратель независимо от других с вероятностью 1/100 голосует за другого кандидата — то есть за того, за которого он голосовать не собирался. (Напомним, что в этих выборах участвуют всего два кандидата.)
Случайная переменная X равна количеству голосов за демократического кандидата D при проведении голосования с возможными ошибками. Определите ожидаемое значение X и объясните ход своих рассуждений при выводе этого значения.
3. В разделе 13.1 описан простой распределенный протокол для решения конкретной задачи разрешения конфликтов. Здесь рассматривается другая ситуация с применением рандомизации для разрешении конфликтов, в которой осуществляется распределенное построение независимого множества.
Предположим, имеется система с n процессами. Между некоторыми парами процессов возникает конфликт (предполагается, что обоим процессам необходим доступ к общему ресурсу). Для заданного интервала времени требуется спланировать выполнение большого подмножества S процессов (остальные процессы при этом не работают), чтобы никакие два конфликтующих процесса не входили в запланированное множество S. Назовем такое множество S бесконфликтным.
Ситуацию можно смоделировать графом G = (V, E), в котором узлы представляют процессы, а ребра соединяют пары процессов, находящихся в конфликте. Легко убедиться в том, что множество процессов S является бесконфликтным в том, и только в том случае, если оно образует независимое множество в G. Это наводит на мысль, что найти бесконфликтное множество Sмаксимального размера для произвольного конфликта G будет сложно (так как обобщенная задача о независимом множестве сводится к этой задаче). Тем не менее мы попробуем найти эвристику для нахождения бесконфликтного множества достаточно большого размера. Также хотелось бы найти простой метод достижения этой цели без централизованного управления: каждый процесс должен обменяться информацией только с небольшим количеством других процессов и затем решить, должен ли он принадлежать множеству S.
В контексте этого вопроса предположим, что у каждого узла в графе G ровно d соседей. (То есть каждый процесс участвует в конфликтах ровно с d другими процессами.)
(а) Рассмотрим следующий простой протокол.
Каждый процесс Рi независимо выбирает случайное значение хi; с вероятностью 1/2 переменной хi присваивается значение 1, и с вероятностью 1/2хi присваивается значение 0. Затем процесс решает войти в множество S в том, и только в том случае, если он выбирает значение 1, и каждый из процессов, с которыми он участвует в конфликте, выбирает значение 0.
Докажите, что множество S, полученное в результате выполнения этого протокола, является бесконфликтным. Также приведите формулу для ожидаемого размера S в отношении к n(количество процессов) и к d (количество конфликтов на один процесс).
(b) Выбор вероятности 1/2 в приведенном выше протоколе был достаточно произвольным, и не так уж очевидно, что он должен обеспечить лучшую эффективность системы. В более общей спецификации протокола вероятность 1/2 заменяется параметром р в диапазоне от 0 до 1 так, как описано ниже.
Каждый процесс Pi независимо выбирает случайное значение xi; с вероятностью p переменной xi присваивается значение 1, и с вероятностью 1 - p xi присваивается значение 0. Затем процесс решает войти в множество S в том, и только в том случае, если он выбирает значение 1, и каждый из процессов, с которыми он участвует в конфликте, выбирает значение 0.
В контексте параметров графа G приведите значение р, максимизирующее ожидаемый размер полученного множества S. Предложите формулу для ожидаемого размера S, когда р присваивается это оптимальное значение.
4. Многие одноранговые системы в Интернете строятся на базе оверлейных сетей. Вместо использования физической топологии Интернета и выполнения с ней необходимых вычислений такие системы используют протоколы, в которых узлы выбирают совокупности виртуальных “соседей” для определения высокоуровневого графа, структура которого имеет минимальное отношение к структуре используемой физической сети. Затем такая оверлейная сеть используется для обмена данными и сервисами и может быть исключительно гибкой по сравнению с физической сетью, которую трудно изменить в реальном времени для адаптации к изменяющимся условиям.
Одноранговые сети обычно растут за счет новых участников, которые присоединяются к существующей структуре. Процесс развития сети оказывает специфическое влияние на характеристики общей сети. За последнее время были исследованы простые абстрактные модели развития сетей, которые дают представление о поведении таких процессов в реальных сетях на качественном уровне.
Рассмотрим простой пример такой модели. Система начинается с одиночного узла v1, после чего узлы присоединяются к ней один за одним; при присоединении узла выполняется протокол с формированием направленного канала связи с другим узлом, выбранным случайно и равномерно из узлов, уже присутствующих в системе. Конкретнее, если система уже содержит узлы v1, v2, ..., vk-1 и узел vk желает присоединиться, он случайным образом выбирает один из узлов v1, v2, ..., vk-1 и устанавливает связь с ним.
Предположим, процесс повторяется вплоть до формирования системы, состоящей из узлов v1, v2, ..., vn; описанная выше случайная процедура создает направленную сеть, в которой каждый узел, кроме v1, имеет ровно один выходной канал. С другой стороны, узел может иметь несколько входных каналов, а может не иметь ни одного. Входные каналы vj представляют все остальные узлы, которые получают доступ к системе через vj; таким образом, если vj имеет много входных каналов, нагрузка на него может оказаться достаточно высокой. Чтобы система была сбалансирована, нам хотелось бы, чтобы узлы имели примерно одинаковое количество входных каналов. Однако в описанной ситуации это маловероятно, так как узлы, присоединенные на более ранней стадии процесса, с большей вероятностью будут иметь больше входных каналов, чем узлы, присоединившиеся позднее. Попробуем дать численную оценку этому дисбалансу.
(a) Для заданного случайного процесса, описанного выше, каково ожидаемое количество входных каналов к узлу vj в такой сети? Приведите точную формулу для n и и попробуйте выразить эту величину асимптотически (выражением без громоздкого суммирования) с использованием записи Ө(∙).
(b) Часть (а) точно выражает смысл, в котором узлы, присоединяемые ранее, получают “несправедливую” долю соединений в сети. Другой способ численного выражения дисбаланса основан на том факте, что при выполнении этого случайного процесса можно ожидать, что многие узлы останутся без входных каналов.
Предложите формулу для ожидаемого количества узлов без входных каналов в сети, развивающейся по условиям описанной выше модели.
5. Где-то в сельской местности n небольших городков решили подключиться к Интернету по оптоволоконному кабелю с высокой пропускной способностью. Городки обозначаются T1, T2, ..., Tn и располагаются вдоль одной длинной дороги, так что город Ti удален на i километров от точки подключения (рис. 13.6).
![]()
Рис. 13.6. Городки T1, ..., Tn должны решить, как им разделить расходы на покупку кабеля
Кабель стоит довольно дорого — k долларов за километр, то есть общая стоимость всего кабеля составляет kn долларов. Представители городков собираются вместе и обсуждают, как им следует разделить расходы на покупку кабеля. Наконец, один из городков на дальнем конце дороги вносит следующее предложение.
Предложение A. Разделить затраты поровну между всеми городками, чтобы каждый платил k долларов.
В каком-то смысле предложение честное: все выглядит так, словно каждый городок платит за километр кабеля, который ведет непосредственно к нему. Но один из представителей городка, расположенного очень близко к точке подключения, резонно указывает, что от более длинного кабеля выигрывают в основном дальние городки, а ближние вполне обошлись бы и коротким кабелем. Поэтому он выдвигает встречное предложение:
Предложение Б. Разделить стоимость так, чтобы вклад городка Ti был пропорционален i, то есть расстоянию до точки подключения.
Представитель другого городка, также очень близкого к точке подключения, указывает, что существует другой способ непропорционального деления, который тоже естествен. Он основан на концептуальном делении кабеля на n “ребер” равной длины е1, ..., en; первое ребро е1 ведет от точки подключения к T1, а i-е (i > 1) ведет от Ti-1 к Ti. Заметим, что хотя е1 используется всеми городками, еn приносит пользу только последнему городку. Так появляется
Предложение В. Разделить стоимость для каждого ребра е. по отдельности. Стоимость еi должна оплачиваться в равной мере городками Ti, Ti+1, ..., Tn, так как они находятся “после” еi.
Итак, вариантов много; какой из них самый справедливый? За ответом на этот вопрос собрание обращается к работе Ллойда Шепли, одного из самых знаменитых экономистов-математиков XX века. Он предложил общий механизм разделения стоимости или прибылей между общими сторонами, который теперь называется распределением Шепли. Этот механизм может рассматриваться как определение “предельного вклада” каждой стороны в предположении, что стороны прибывают в случайном порядке.
В условиях нашей задачи произойдет следующее: возьмем упорядочение О городков и предположим, что городки “прибывают” в этом порядке. Предельная стоимость городка Ti в порядке О определяется следующим образом: если Ti является первым в порядке О, то Ti платит ki — стоимость всего кабеля на всем отрезке от точки подключения до Ti. В противном случае алгоритм просматривает множество городков, предшествующих Ti в порядке О; допустим, из этих городков Tj находится на наибольшем расстоянии от точки подключения. При прибытии Tiпредполагается, что кабель уже проложен до Tj, но не далее. Итак, если j > i (Tj находится дальше Ti), предельная стоимость Ti равна 0, так как кабель уже проходит мимо Ti на своем пути к Tj. С другой стороны, если j < i, то предельная стоимость Ti равна k(i - j): это стоимость продления кабеля от Tj к Ti. (Предположим, n = 3, и городки прибывают в порядке T1, T3, T2. Сначала T1платит k при прибытии. Затем прибывает T3, которому достаточно заплатить 2k для продления кабеля от T1. Наконец, при прибытии T2 платить вообще ничего не нужно, так как кабель уже проложен мимо этого городка до T3.)
Пусть Xi — случайная переменная, равная предельной стоимости городка Ti при случайном равномерном выборе порядка О из всех перестановок множества городков. По правилам распределения Шепли величина, которую городок Ti должен внести в общую стоимость кабеля, равна ожидаемому значению X.
Вопрос: какое из трех предложений (если оно есть) обеспечивает такое же распределение стоимостей, как механизм распределения Шепли? Приведите доказательство ответа.
6. Одна из (многих) сложных задач, связанных с расшифровкой генома, может быть сформулирована следующим абстрактным способом. Имеется множество из n маркеров {μ1 ..., μn} — позиций в хромосоме, требуется вывести линейное упорядочение этих маркеров. Вывод должен удовлетворять множеству k ограничений, каждое из которых задается триплетом (μi, μj, μk) и требует, чтобы маркер μj находился между μi и μk в общем упорядочении). (Обратите внимание: это ограничение не указывает, какой из маркеров μi или μk должен находиться на первом месте в упорядочении, а лишь требует, чтобы маркер μj находился между ними).
Одновременное выполнение всех ограничений не всегда возможно, поэтому требуется получить упорядочение, выполняющее как можно больше из них. К сожалению, принятие решения о существовании упорядочения, выполняющего не менее k' из k ограничений, является NР-сложной задачей (доказывать это не нужно).
Приведите константу α > 0 (не зависящую от n) и алгоритм, обладающий следующим свойством: если возможно выполнить k* ограничений, то алгоритм выдает упорядочение маркеров, выполняющее не менее αk* ограничений. Алгоритм может быть рандомизированным; в таком случае он должен выдавать упорядочение, для которого ожидаемое количество выполненных ограничений не менее αk*.
7. В разделе 13.4 был разработан аппроксимирующий алгоритм для задачи MAX 3-SAT с множителем 7/8, в котором предполагалось, что каждое условие содержит составляющие для трех разных переменных. В этой задаче рассматривается похожая задача MAX SAT: для заданного множества условий С1, ..., Сk по множеству переменных X = {x1,..., xn} найти логическое присваивание, выполняющее как можно большее количество условий. Каждое условие содержит минимум один литерал, и все переменные в одном условии различны, но в остальном никакие допущения относительно длины условий не делаются: одни условия могут состоять из многих переменных, а другие содержат всего одну.
(a) Сначала рассмотрим рандомизированный аппроксимирующий алгоритм, который мы использовали для задачи MAX 3-SAT, с независимым присваиванием каждой переменной истинного или ложного значения с вероятностью 1/2. Покажите, что ожидаемое количество условий, выполненных этим случайным присваиванием, не менее k/2, то есть в ожидании выполняется по меньшей мере половина условий. Приведите пример, показывающий, что существуют экземпляры задачи MAX SAT, в которых никакое присваивание не выполняет более половины условий.
(b) Если имеется условие, состоящее только из одного литерала (например, условие, включающее только х1 или только ![]() ), то оно может быть выполнено только одним способом: нужно присвоить переменной соответствующее значение. Если есть два условия, одно из которых состоит только из х., а другое из его отрицания, возникает довольно очевидное противоречие.
), то оно может быть выполнено только одним способом: нужно присвоить переменной соответствующее значение. Если есть два условия, одно из которых состоит только из х., а другое из его отрицания, возникает довольно очевидное противоречие.
Предположим, в нашем экземпляре нет таких “прямых конфликтов”, то есть не существует переменной хi, для которой условие С = {хi} существует одновременно с условием ![]() Измените приведенную выше рандомизированную процедуру, чтобы улучшить коэффициент аппроксимации с 1/2 до минимум 0,6. Другими словами, измените алгоритм так, чтобы ожидаемое количество условий, выполняемых процессом, было не менее 0,6k.
Измените приведенную выше рандомизированную процедуру, чтобы улучшить коэффициент аппроксимации с 1/2 до минимум 0,6. Другими словами, измените алгоритм так, чтобы ожидаемое количество условий, выполняемых процессом, было не менее 0,6k.
(c) Предложите рандомизированный алгоритм с полиномиальным временем для обобщенной задачи MAX SAT, при котором ожидаемое количество условий, выполняемых алгоритмом, лежит в пределах множителя 0,6 от максимума. (Учтите, что по аналогии с (a) существуют экземпляры, в которых невозможно выполнить более k/2 условий; суть в том, что нам хотелось бы иметь эффективный алгоритм, способный в ожидании выполнить до 0,6 части условий от максимума, выполняемого при оптимальном присваивании.)
8. Имеется ненаправленный граф G = (V, E) с n узлами и m ребрами. Для подмножества X ⊆ V запись G[X] будет обозначать подграф, индуцированный по X, — то есть граф, множеством узлов которого является X, а множество ребер состоит из всех ребер G, оба конца которых принадлежат X.
Для заданного натурального числа k ≤ n требуется найти множество из k узлов, индуцирующее из G “плотный” подграф. Или в более точной формулировке, предложите алгоритм с полиномиальным временем, который выдает для заданного натурального числа k ≤ n множество X ⊆ V из k узлов, обладающее тем свойством, что индуцированный подграф G[X] содержит минимум ![]() ребер.
ребер.
Приведите либо (a) детерминированный алгоритм, либо (b) рандомизированный алгоритм с полиномиальным оиждаемым временем выполнения, который выводит только правильные ответы.
9. Допустим, вы разрабатываете стратегии для продажи товаров на популярном аукционном сайте. В отличие от других аукционных сайтов, на вашем используется однопроходной аукцион, в котором каждая ставка либо немедленно (и безвозвратно) принимается, либо отклоняется. Ниже приведена более конкретная схема работы сайта.
• Продавец выставляет товар для продажи.
• Покупатели приходят последовательно.
• При появлении покупатель i делает ставку bi > 0.
• Продавец немедленно решает, принять эту ставку или нет. Если ставка принята, то товар продается, а будущие покупатели теряют возможность его купить. Если ставка отклонена, то покупатель i уходит, а ставка отменяется; только после этого продавец сможет увидеть заявки будущих покупателей. Предположим, товар выставлен на продажу и имеются n покупателей с разными ставками. Также предположим, что покупатели приходят в случайном порядке и продавцу известно количество n покупателей. Требуется разработать стратегию, при которой у продавца имеется разумная вероятность принять максимальную из n заявок. Под “стратегией” подразумевается правило, по которому продавец решает, принять или отклонить каждую ставку, на основании исключительно значения n и последовательности ставок, сделанных до настоящего момента.
Например, продавец всегда может принимать первую ставку. В результате вероятность того, что он примет высшую из n заявок, составит всего 1/n, так как высшая ставка должна оказаться первой из поданных.
Предложите стратегию, при которой продавец принимает высшую из n ставок с вероятностью не менее 1/4 независимо от значения n. (Для простоты считайте, что число n четно.) Докажите, что ваша стратегия обеспечивает эту вероятностную гарантию.
10. Рассмотрим очень простую систему проведения веб-аукциона, которая работает следующим образом. Имеются n агентов; агент i делает ставку bi, которая является положительным целым числом. Будем считать, что все ставки bi отличны друг от друга. Агенты появляются в порядке, выбираемом случайным образом с равномерным распределением, каждый делает свою ставку bi, а система постоянно поддерживает переменную b* равную наивысшей из сделанных на данный момент ставок. (Переменная b* инициализируется 0.)
Приведите оценку ожидаемого количества обновлений b* при выполнении этой процедуры как функцию параметров задачи.
Пример. Допустим, b1 = 20, b2 = 25 и b3 = 10, а агенты прибывают в порядке 1, 3, 2. Тогда b* обновляется для заявок агентов 1 и 2, но не для 3.
11. Алгоритмы распределения нагрузки для параллельных или распределенных систем стремятся равномерно распределить группу вычислительных заданий по нескольким машинам. Это делается для того, чтобы избежать пиковых нагрузок на отдельных машинах. Если централизованная координация возможна, то нагрузка может быть распределена почти идеально. Но что, если задания поступают из разных источников, которые не могут координироваться? Как было показано в разделе 13.10, задания можно распределять между машинами случайным образом, надеясь, что рандомизация поможет предотвратить несбалансированность. Разумеется, такое решение в общем случае уступает идеальному централизованному решению, но оно может быть вполне эффективным. Попробуем проанализировать некоторые вариации и расширения простой эвристики распределения нагрузки, описанной в разделе 13.10.
Предположим, имеются k машин и k заданий, ожидающих обработки. Каждое задание назначается на одну из k машин независимо и случайным образом (с равной вероятностью для всех машин).
(a) Обозначим N(k) ожидаемое количество машин, не получивших ни одного задания, так что N(k)/k — ожидаемая часть бездействующих машин. Чему равен предел ![]() Приведите доказательство.
Приведите доказательство.
(b) Допустим, машины не могут ставить в очередь лишние задания, так что если случайное распределение назначает на машину M больше одного задания, то M выполняет первое из полученных заданий и отклоняет все остальные. Пусть R(k) — ожидаемое количество отклоненных заданий; соответственно R(k)/k — ожидаемая часть отклоненных заданий. Чему равен предел ![]() Приведите доказательство.
Приведите доказательство.
(c) Предположим, машины имеют встроенный буфер чуть большего размера; каждая машина M выполняет первые два полученных задания и отклоняет все остальные. Обозначим R2(k) ожидаемое количество заданий, отклоненных по этому правилу. Чему равен предел ![]() Приведите доказательство.
Приведите доказательство.
12. Рассмотрим аналогию с алгоритмом Каргера для нахождения минимального разреза s-t. Ребра будут стягиваться в итеративном режиме с использованием рандомизированной процедуры. Пусть в заданной итерации s и t — (возможно) стянутые узлы, содержащие исходные узлы s и t соответственно. Чтобы гарантировать, что узлы s и t не будут сжаты, на каждой итерации удаляются все ребра, соединяющие s и t, а стягиваемое ребро выбирается случайным образом среди остальных ребер. Приведите пример, показывающий, что вероятность нахождения этим методом минимального разреза s-t может быть экспоненциально малой.
13. Рассмотрим классический эксперимент с шарами и корзинами. Как обычно, каждый шар независимо попадает в одну из двух корзин, при этом попадание в каждую из корзин равновероятно. Ожидаемое количество шаров в каждой корзине равно n. В этой задаче исследуется вопрос возможной величины их разности. Пусть Х1 и Х2 — количество шаров в первой и второй корзине соответственно (X1 и X2 — случайные переменные). Докажите, что для любого ε > 0 существует константа с > 0, для которой вероятность ![]()
14. Ученые, разрабатывающие параллельные физические модели, обращаются к вам по поводу следующей задачи. Имеется множество P из k базовых процессов, требуется назначить каждый процесс на одну из двух машин M1 или M2. Затем они будут выполнять серию из n заданий J1, ..., Jn. Каждое задание Ji представляется множеством Pi ⊆ Р из ровно 2n базовых процессов, которые должны выполняться (каждый на назначенной машине) во время обработки задания. Распределение базовых процессов по машинам называется идеально сбалансированным, если для каждого задания Ji ровно n базовых процессов, связанных с Ji, были назначены на каждую из двух машин. Распределение базовых процессов между машинами будет называться почти сбалансированным, если для каждого задания Ji не более 4/3n базовых процессов, связанных с Ji, были назначены на одну машину.
(a) Покажите, что для произвольно больших значений n существуют серии заданий J1, ..., Jn, для которых не существует идеально сбалансированного распределения.
(b) Предположим, n ≥ 200. Предложите алгоритм, который получает произвольную серию заданий J1, ..., Jn, и строит почти сбалансированное распределение базовых процессов между машинами. Ваш алгоритм может быть рандомизированным; в этом случае ожидаемое время выполнения должно быть полиномиальным и алгоритм всегда должен выдавать правильный ответ.
15. Предположим, имеется очень большое множество S вещественных чисел, и вы хотите вычислить предполагаемую медиану этих чисел на основании выборки. Можно считать, что все числа в S различны. Пусть n = |S|; число х будет называться ε-приближенной медианой S, если по крайней мере ![]() чисел в S меньше х и по крайней мере
чисел в S меньше х и по крайней мере ![]() чисел в S больше х.
чисел в S больше х.
Рассмотрим алгоритм, который выбирает случайное подмножество S' ⊆ S с равномерным распределением, вычисляет медиану S' и возвращает ее как приближенную медиану S. Покажите, что существует абсолютная константа с, независимая от n, так что при применении алгоритма с выборкой S' размера с с вероятностью 0,99 возвращаемое число будет (0,05)-приближенной медианой S. (Рассмотрите либо версию алгоритма, строящую S' посредством формирования выборки с заменой, чтобы элемент S мог выбираться многократно, либо версию без замены.)
16. Рассмотрим следующий (частично определенный) метод безопасной передачи сообщения между отправителем и получателем. Сообщение будет представлено в виде битовой строки. Пусть ∑ = {0,1} и ∑* — множество всех строк из 0 и более битов (например, 0,00,1110001 ∈ ∑*). “Пустая строка”, не содержащая битов, будет обозначаться λ ∈ ∑*.
Отправитель и получатель совместно используют секретную функцию f: ∑* x ∑ → ∑. Иначе говоря, f получает слово и бит и возвращает бит. Получая последовательность битов α ∈ ∑*, получатель выполняет следующий метод для ее расшифровки.

Происходящее можно рассматривать как своего рода “потоковый шифр с обратной связью”. Недостаток такого решения заключается в том, что если любой бит αi будет поврежден при передаче, он повредит вычисленное значение βj для всех j ≥ i.
Рассмотрим следующую задачу: отправитель S хочет передать сообщение (простой текст) β каждому из k получателей R1, ..., Rk. С каждым получателем он обменивается секретной функцией f(i) (разной для разных получателей). Затем каждому получателю отправляется свое зашифрованное сообщение α(i), такое что α(i) расшифровывается в β при выполнении описанного выше алгоритма с функцией f(i).
К сожалению, каналы связи сильно зашумлены, и каждый из n битов в каждой из k передач подвергается независимому искажению (то есть принимает противоположное значение) с вероятностью 1/4. Таким образом, любой получатель с большой вероятностью не сможет расшифровать сообщение сам по себе. Покажите, что если значение k достаточно велико как функция n, то k получателей смогут совместными усилиями восстановить текстовое сообщение: для этого они собираются вместе и, не раскрывая никакие из α(i) или f(i), в интерактивном режиме выполняют алгоритм, который строит правильное содержимое β с вероятностью не менее 9/10. (Насколько большим должно быть значение k в вашем алгоритме?)
17. Рассмотрим простую модель азартной игры при неблагоприятных шансах. В начале общий выигрыш равен 0. Проводится серия из n раундов; в каждом раунде выигрыш возрастает на 1 с вероятностью 1/3 и убывает на 1 с вероятностью 2/3.
Покажите, что для ожидаемого количества шагов, при котором выигрыш положителен, можно определить верхнюю границу в виде абсолютной константы, не зависящей от значения n.
18. В этой задаче рассматривается рандомизированный алгоритм для задачи о вершинном покрытии.

Нас интересует ожидаемая стоимость вершинного покрытия, выбираемого этим алгоритмом.
(a) Является ли этот алгоритм с-аппроксимирующим алгоритмом для задачи о вершинном покрытии с минимальным весом для некоторой константы с? Докажите свой ответ.
(b) Является ли этот алгоритм с-аппроксимирующим алгоритмом для задачи о вершинном покрытии с минимальной мощностью для некоторой константы с? Докажите свой ответ.
Подсказка: обозначим pe вероятность того, что ребро e выбирается как непокрытое ребро в этом алгоритме. Сможете ли вы выразить ожидаемое значение решения через эти вероятности? Чтобы ограничить значение оптимального решения в контексте вероятностей рe, попробуйте ограничить сумму вероятностей для ребер, инцидентных заданной вершине v, а именно ![]()
Примечания и дополнительная литература
В области применения рандомизации в алгоритмах ведутся активные исследования; в частности, этой теме посвящены книги Мотвани и Рагхавана (Motwani, Raghavan, 1995), а также Митценмахера и Упфала (Mitzenmacher, Upfal, 2005). Как видно из материала этой главы, вероятностные аргументы, используемые при изучении базовых рандомизированных алгоритмов, часто имеют дискретный, комбинаторный оттенок; такой стиль вероятностного анализа рассматривается в книге Феллера (Feller, 1957).
Применение рандомизации для разрешения конфликтов типично для многих систем и сетевых приложений. Например, в коммуникационных средах в стиле Ethernet рандомизированные протоколы используются для сокращения количества коллизий между разными отправителями; эта тема рассматривается в книге Бертсекаса и Галлагера (Bertsekas, Gellager, 1992).
Рандомизированный алгоритм для задачи о минимальном разрезе, описанной в тексте, был разработан Каргером. После дополнительных оптимизаций Каргера и Штейна (Karger, Stein, 1996) он стал одним из самых эффективных методов решения задачи о минимальном разрезе. Дополнительные расширения и возможности применения алгоритма описаны в диссертации Каргера (Karger, 1995).
Аппроксимирующий алгоритм для задачи MAX 3-SAT был разработан Джонсоном (Johnson, 1974) для статьи, в которой были опубликованы ранние аппроксимирующие алгоритмы для NР-сложных задач. Неожиданный вывод из этого раздела — что каждый экземпляр 3-SAT имеет присваивание, выполняющее не менее 7/8 условий, — является примером вероятностного метода, тогда как существование комбинаторной структуры с нужным свойством аргументируется просто тем, что случайная структура обладает данным свойством с положительной вероятностью. В этой области комбинаторики были проведены серьезные исследования; многие практические применения данного метода описаны в книге Элона и Спенсера (Alon, Spencer, 2000).
Хеширование стало предметом самостоятельных масштабных исследований (как в теоретических, так и в практических условиях), и у базового метода существует много разновидностей. Метод, которому посвящен раздел 13.6, был предложен Картером и Вегманом (Carter, Wegman, 1979). Идея применения рандомизации для нахождения ближайшей пары точек на плоскости была предложена Рабином (Rabin, 1976) в авторитетной ранней статье, посвященной применению рандомизации во многих алгоритмических ситуациях. Алгоритм, описанный в этой главе, был разработан Голином и др. (Golin, 1995). Метод, применяемый для ограничения количества операций со словарем, в котором суммируется ожидаемая работа по всем этапам в случайном порядке, иногда называется обратным анализом; изначально он был предложен Чу (Chew, 1985) для сопутствующей геометрической задачи. Другие применения обратного анализа описаны в работе Зейдела (Seidel, 1993).
Гарантии эффективности для алгоритма кэширования LRU принадлежат Слитору и Тарьяну (Steator, Torjan, 1985), а авторами границы рандомизированного алгоритма маркировки являются Фиат, Карп, Лаби, Макгиох, Слитор и Янг (Fiat, Karp, Luby, McGeoch, Sleator, Young, 1991). На более общем уровне в статье Слитора и Тарьяна выделяется понятие оперативных алгоритмов, которые должны обрабатывать входные данные без информации о будущем; кэширование — одна из фундаментальных областей, требующих применения таких алгоритмов. Теме оперативных алгоритмов посвящена книга Бородина и Эль-Янива (Borodin, El-Yaniv, 1998), в которой приведено много других результатов, относящихся к кэшированию.
Существует много других способов формулировки границ из раздела 13.9, демонстрирующих, что значительное отклонение суммы независимых случайных переменных, принимающих значения 0 и 1, от среднего значения маловероятно. Результаты такого рода обычно называются границами Чернова или границами Чернова-Хеффдинга на основании работ Чернова (Chernoff, 1952) и Хеффдинга (Hoeffding, 1963). В книгах Элона и Спенсера (Alon, Spencer, 1992), Мотвани и Рагхавана (Motwani, Raghavan, 1995), Митценмахера и Упфала (Mitzenmacher, Upfal, 2005) такие границы рассматриваются более подробно, с дополнительными примерами применения.
Результаты пакетной маршрутизации в контексте максимальной длины и максимальной загрузки были получены Лейтоном, Маггсом и Рао (Leighton, Maggs, Rao, 1994). Маршрутизация — еще одна область, в которой рандомизация эффективно работает на сокращение конфликтов и пиковых нагрузок; многие применения этого принципа рассматриваются в книге Лейтона (Leighton, 1992).
Примечания к упражнениям
Упражнение 6 основано на результатах Бенни Чора и Мадху Судана; упражнение 9 представляет собой версию “задачи о секретаре”, популяризация которой часто приписывается Мартину Гарднеру.
1 Однако это не самый простой способ включения рандомизации в алгоритм кэширования. Можно рассмотреть чисто случайный алгоритм, который отказывается от самой концепции маркировки и при каждом кэш-промахе выбирает один из k текущих элементов для вытеснения случайным образом. (Обратите внимание на различие: рандомизированный алгоритм маркировки выполняет рандомизацию только среди непомеченных элементов.) Хотя здесь это не доказывается, чисто случайный алгоритм может породить по крайней мере в с раз больше промахов, чем оптимум, для любой константы с < k, поэтому он не обеспечивает выигрыша по сравнению с LRU.