Алгоритмы - Разработка и применение - 2016 год
Первое рекуррентное отношение: алгоритм сортировки слиянием - Разделяй и властвуй
Термином “разделяй и властвуй” обозначается класс алгоритмических методов, которые разбивают входные данные на несколько частей, рекурсивно решают задачу для каждой части, а затем объединяют решения подзадач в одно общее решение. Во многих случаях такие решения оказываются весьма простыми и эффективными.
Анализ времени выполнения алгоритма категории “разделяй и властвуй” обычно подразумевает вычисление рекуррентного соотношения, которое устанавливает рекурсивную границу времени выполнения в контексте времени выполнения меньших экземпляров. Глава открывается общим обсуждением рекуррентных отношений; вы увидите, как они встречаются в процессе анализа и какие методы используются для установления верхних границ на их основе.
Затем будет описано использование принципа “разделяй и властвуй” в разных предметных областях: вычисление функции расстояния для разных вариантов ранжирования множества объектов; поиск ближайшей пары точек на плоскости; умножение двух целых чисел; и сглаживание сигнала с шумом. Принцип “разделяй и властвуй” также встречается в последующих главах, поскольку этот метод часто хорошо работает в сочетании с другими методами разработки алгоритмов. Например, в главе 6 он будет применен в сочетании с динамическим программированием для создания эффективного по затратам памяти решения фундаментальной задачи сравнения последовательностей, а в главе 13 он используется в сочетании с рандомизацией для создания простого и эффективного алгоритма вычисления медианы для множества чисел.
У многих ситуаций, в которых применяется принцип “разделяй и властвуй” (включая перечисленные), есть нечто общее: естественный алгоритм “грубой силы” может выполняться за полиномиальное время, а стратегия “разделяй и властвуй” способна сократить время выполнения до многочлена меньшей степени. В этом отношении он отличается от многих задач из предыдущих глав, например от задач, в которых алгоритм “грубой силы” работал с экспоненциальным временем, а целью разработки более сложного алгоритма был переход к полиномиальному времени. Например, как упоминалось в главе 2, естественный алгоритм “грубой силы” для поиска ближайшей пары среди n точек на плоскости просто проверяет все Ө(n2) расстояний с (полиномиальным) временем выполнения Ө(n2). Принцип “разделяй и властвуй” позволит улучшить время выполнения до O(n log n). Таким образом, на высоком уровне общая тема этой главы не отличается от того, что мы уже видели ранее: улучшение результатов поиска “грубой силой” становится фундаментальной концептуальной проблемой на пути эффективного решения задачи, и проектирование сложного алгоритма помогает с ней справиться. Просто различия между поиском методом “грубой силы” и улучшенным решением не всегда означают различия между экспоненциальным и полиномиальным временем.
5.1. Первое рекуррентное отношение: алгоритм сортировки слиянием
Чтобы понять общий подход к анализу алгоритмов “разделяй и властвуй”, начнем с алгоритма сортировки слиянием. Этот алгоритм уже упоминался в главе 2, когда мы рассматривали типичное время выполнения некоторых алгоритмов. Алгоритм сортировки слиянием сортирует список чисел: сначала список делится на две половины, каждая половина рекурсивно сортируется по отдельности, после чего результаты рекурсивных вызовов (в форме двух отсортированных половин) объединяются алгоритмом слияния отсортированных списков, представленным в главе 2.
Чтобы проанализировать время выполнения сортировки слиянием, мы абстрагируем поведение алгоритма в следующий шаблон, описывающий многие типичные алгоритмы “разделяй и властвуй”.
(√) Разбить входные данные на два блока равного размера; рекурсивно решить две подзадачи для этих блоков по отдельности; объединить два результата в одно решение, с линейными затратами времени для исходного деления и итогового объединения.
В алгоритме сортировки слиянием, как и в любом алгоритме этого типа, также необходим базовый случай рекурсии, который обычно завершает выполнение для входных данных некоторого постоянного размера. В случае сортировки слиянием предполагается, что при достижении размера 2 рекурсия останавливается, а два элемента сортируются простым сравнением.
Рассмотрим любой алгоритм, построенный по шаблону (√); обозначим T(n) худшее время выполнения для входных данных с размером n. Если предположить, что n четно, алгоритм за время O(n) делит входные данные на два блока с размером n/2, а затем тратит время T(n/2) на решение каждой производной задачи (T(n/2) — худшее время выполнения для входных данных с размером n/2); и наконец, время O(n) тратится на объединение решений из двух рекурсивных вызовов. Это время выполнения T(n) удовлетворяет следующему рекуррентному отношению.
(5.1) Для некоторой константы с,
T(n) ≤ 2T(n/2) + cn
для n > 2, и
T(2) ≤ с.
Структура (5.1) типична для рекуррентных отношений: имеется неравенство или равенство, ограничивающее T(n) в выражении, использующем T(k) для меньших значений k, и существует базовый случай, который фактически сообщает, что T(n) является константой для константы n. Также заметьте, что (5.1) можно записать неформально в виде T(n) ≤ 2T(n/2) + O(n), исключив константу c. Тем не менее явное включение c обычно бывает полезно при анализе рекуррентных отношений.
Чтобы упростить описание, мы будем считать, что параметры (такие, как n) четные. Такое предположение создает некоторую неточность; без него два рекурсивных вызова будут применяться к задачам размера [n/2], а рекуррентное отношение должно иметь вид
![]()
для n ≥ 2. Однако для всех рекуррентных отношений, которые мы будем рассматривать (и которые встречаются на практике), игнорирование верхней или нижней границы чисел обычно не влияет на асимптотические границы, а формулы заметно упрощаются.
Учтите, что (5.1) не дает явной асимптотической границы для скорости роста функции T, скорее T(n) задается неявно в контексте его значений для входных данных меньшего размера. Для получения явной границы необходимо разрешить рекуррентное отношение так, чтобы обозначения T присутствовали только в левой части неравенства.
Задача разрешения рекуррентности была встроена в некоторые стандартные компьютерные алгебраические системы, а многие стандартные рекуррентные отношения успешно разрешаются автоматизированными средствами. Тем не менее будет полезно разобраться в процессе разрешения рекуррентности и научиться распознавать рекуррентные отношения, приводящие к хорошему времени выполнения, — разработка эффективных алгоритмов “разделяй и властвуй” тесно связана с пониманием того, как рекуррентное отношение определяет время выполнения.
Методы разрешения рекуррентности
Существуют два основных подхода к разрешению рекуррентности.
Самый естественный и понятный подход к поиску решения — “раскрутка” рекурсии с отслеживанием времени выполнения на нескольких начальных уровнях и выявлением закономерности, которая сохраняется в ходе рекурсии. Затем время выполнения суммируется по всем уровням рекурсии (то есть до достижения нижнего предела для подзадач постоянного размера) с получением общего времени выполнения.
Во втором варианте строится гипотеза, которая подставляется в рекуррентное отношение и проверяется на жизнеспособность. Для формальной проверки таких подстановок используется индукция по n. Существует полезная разновидность этого метода, в которой известна общая форма решения, но неизвестны точные значения всех параметров. Оставляя эти параметры неопределенными в подстановке, часто удается подобрать их по мере необходимости.
А теперь мы обсудим каждый из этих методов на примере рекуррентного отношения (5.1).
Раскрутка рекуррентности в алгоритме сортировки слиянием
Начнем с первого способа разрешения рекуррентности в (5.1). Основная идея представлена на рис. 5.1.

Рис. 5.1. Раскрутка рекуррентности T(n) ≤ 2T(n/2) + O(n)
♦ Анализ нескольких начальных уровней: на первом уровне рекурсии имеется одна задача с размером n, которая выполняется за время cn плюс время, потраченное на все последующие рекурсивные вызовы. На следующем уровне имеются две задачи с размером n/2. Каждая задача выполняется за время максимум cn/2, что дает в сумме cn плюс время последующих рекурсивных вызовов. На третьем уровне используются четыре задачи с размером n/4, каждая выполняется за время cn/4, итого максимум cn.
♦ Выявление закономерности: что вообще происходит? На уровне j рекурсии количество подзадач удваивается j раз и поэтому равно 2j. Каждая задача соответственно уменьшается вдвое j раз; следовательно, размер каждой подзадачи равен n/2j, и она выполняется за время максимум cn/2j. Таким образом, вклад уровня j в общее время выполнения составляет максимум 2j(cn/2j) = cn.
♦ Суммирование по всем уровням рекурсии: выясняется, что у рекурсии из (5.1) общий объем работы, выполняемой на каждом уровне, имеет одну и ту же верхнюю границу cn. Количество делений входных данных для сокращения их размера с n до 2 составляет log2 n. Суммируя объем работы cn по log n уровням рекурсии, получаем общее время выполнения O(n log n).
Следующее утверждение подводит итог анализа.
(5.2) Любая функция T(∙), удовлетворяющая условию (5.1), имеет границу O(n log n) при n > 1.
Подстановка решения в рекуррентное отношение сортировки слиянием
Аргументы, которые позволили прийти к выводу (5.2), могут использоваться для определения того, что функция T(n) ограничивается O(n log n). С другой стороны, если у вас имеется гипотеза относительно времени выполнения, ее можно проверить, подставив ее в рекуррентное отношение.
Допустим, вы предполагаете, что T(n) ≤ cn log2 n для всех n ≥ 2, и хотите проверить, так ли это. Для n = 2 оценка очевидно верна, так как в этом случае cn log2 n = 2c, а в (5.1) явно указано, что T(2) ≤ c. Теперь предположим по индукции, что T(m) ≤ cm log2 m для всех значений m, меньших n; теперь нужно доказать, что гипотеза выполняется для T(n). Для этого запишем рекуррентное отношение для T(n) и подставим его в неравенство T(n/2) ≤ c(n/2)log2(n/2). Полученное выражение можно упростить, если заметить, что log2(n/2) = (log2 n) - 1. Ниже приведены полные вычисления.
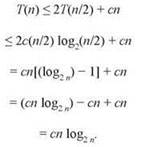
Искомая граница для T(n) доказана в предположении, что она действительна для меньших значений m < n; рассуждение по индукции завершено.
Использование частичной подстановки
Также существует более слабый вид подстановки, в котором предполагается общая форма решения без точных значений всех констант и других параметров.
Предположим, вы считаете, что T(n) = O(n log n), но не уверены в константе в обозначении O(∙). Метод подстановки может использоваться даже без точного значения этой константы. Сначала записываем T(n) ≤ kn logb n для некоторой константы k и основания b, которые будут определены позднее.
(Вообще говоря, основание и константа связаны друг с другом, так как основание логарифма можно изменить простым умножением на константу, — см. главу 2.)
Теперь хотелось бы знать, существуют ли значения k и b, которые будут работать в индукции. Для начала проверим один уровень индукции.
![]()
Появляется естественная мысль выбрать для логарифма основание b = 2, поскольку мы видим, что это позволит применить упрощение log2(n/2) = (log2 n) - 1. Продолжая с выбранным значением, получаем
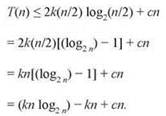
Наконец, спросим себя: можно ли подобрать значение k, при котором последнее выражение будет ограничиваться kn log2 n? Очевидно, что ответ на этот вопрос положителен; просто нужно выбрать любое значение k, не меньшее c, и мы получаем
![]()
Индукция завершена.
Итак, метод подстановки может пригодиться для определения точных значений констант, если у вас уже имеется некоторое представление об общей форме решения.