Алгоритмы - Разработка и применение - 2016 год
Поиск малых вершинных покрытий - Расширение пределов разрешимости
Хотя в начале книги изучались методы эффективного решения задач, в последних главах мы какое-то время занимались классами задач, для которых, как считается, эффективных решений не существует (АР-полными и PSPACE-полными задачами). И на основании того, что мы при этом узнали, был неявно сформирован двусторонний подход к решению новых вычислительных задач: сначала мы пытаемся найти эффективный алгоритм; а если попытка оказывается неудачной, мы пытаемся доказать его АР-полноту (или даже PSPACE-полноту). Если один из этих двух методов оказывается успешным, вы получаете либо решение проблемы (алгоритм), либо веское “обоснование” возникших трудностей: эта задача по крайней мере не проще многих знаменитых задач из области вычислительной теории.
К сожалению, на этой стратегии далеко не уедешь. Если существует задача, которую действительно важно решить, вряд ли кто-нибудь удовлетворится вашим заявлением о том, что задача является NР-сложной1 и на нее не стоит тратить время. От вас хотят увидеть, как можно лучшее решение — даже если оно и не является точным или оптимальным. Например, в задаче о независимом множестве, даже если мы не можем найти самое большое независимое множество в графе, все равно будет естественно проводить вычисления в пределах возможного времени и выдать независимое множество наибольшего размера, которое удастся найти.
Следующая часть книги будет посвящена различным аспектам этой проблемы. В главах 11 и 12 мы рассмотрим алгоритмы, предоставляющие приближенные ответы с гарантированными границами ошибки за полиномиальное время; также будут рассмотрены эвристики локального поиска, которые на практике часто оказываются очень эффективными, даже если мы не можем предоставить никаких доказуемых гарантий относительно их поведения.
Но для начала рассмотрим несколько ситуаций, в которых возможно точное решение экземпляров АР-полных задач с разумной эффективностью. Как появляются такие ситуации? Вспомните основной смысл АР-полноты: экземпляры этих задач в худшем случае очень сложны и, скорее всего, не решаются за полиномиальное время. Однако конкретный экземпляр задачи может и не оказаться “худшим случаем” — более того, может оказаться, что рассматриваемый экземпляр имеет особую структуру, которая упрощает задачу. Итак, в этой главе мы рассмотрим ситуации, в которых можно дать количественную оценку “простоты” данного экземпляра по сравнению с худшим случаем, чтобы использовать эти ситуации при их возникновении.
Этот принцип будет рассмотрен в нескольких конкретных ситуациях. Сначала мы займемся задачей о вершинном покрытии, для экземпляров которой существуют два естественных параметра “размера”: размер графа и размер искомого вершинного покрытия. ЖР-полнота вершинного покрытия предполагает, что решение должно быть экспоненциальным (по крайней мере) по одному из этих параметров; но разумный выбор того, какого именно, может оказать огромное влияние на время выполнения.
Затем мы исследуем идею о том, что многие NР-полные задачи графов становятся решаемыми за полиномиальное время, если потребовать, чтобы входные данные представляли собой дерево. Это конкретная иллюстрация того, как ввод с “особой структурой” позволяет избежать многих сложностей, из-за которых худший случай становится неразрешимым. Вооружившись этой информацией, концепцию дерева можно обобщить до более общего класса графов (имеющих малую ширину) и показать, что многие NР-полные задачи также разрешимы для этого более общего класса.
Впрочем, при этом следует подчеркнуть, что основное положение остается неизменным: экспоненциальные алгоритмы очень плохо масштабируются. В этой главе представлены некоторые способы обойти эту проблему, которые бывают очень эффективными в разных ситуациях, но, очевидно, для полностью обобщенного случая обходного пути не существует. Именно по этой причине мы займемся изучением алгоритмов аппроксимации и локального поиска в следующих главах.
10.1. Поиск малых вершинных покрытий
Припомним задачу о вершинном покрытии, представленную в главе 8 при изучении NР-полноты. Для заданного графа G = (V, E) и целого k нам хотелось бы найти вершинное покрытие с размером не более k, то есть множество узлов S ⊆ V с размером |S| ≤ k, для которого по крайней мере один конец каждого ребра e ∈ E принадлежит S.
Как и многие NР-полные задачи принятия решений, задача о вершинном покрытии имеет два параметра: n (количество узлов в графе) и k (допустимый размер вершинного покрытия). Это означает, что диапазон возможных границ времени выполнения становится менее тривиальным, поскольку в нем приходится учитывать взаимодействие этих двух параметров.
Задача
Рассмотрим это взаимодействие между параметрами n и k более подробно. Прежде всего замечаем, что если k является фиксированной константой (например, k = 2 или k = 3), задача о вершинном покрытии решается за полиномиальное время: мы просто проверяем все подмножества V с размером k и смотрим, образует ли какое-нибудь из них вершинное покрытие. Всего таких подмножеств ![]() и на проверку того, является ли каждое из них вершинным покрытием, требуется время O(kn); общее время составляет
и на проверку того, является ли каждое из них вершинным покрытием, требуется время O(kn); общее время составляет ![]() Из этого мы видим, что неразрешимость задачи о вершинном покрытии реально проявляется только при росте k как функции n. Однако даже для умеренно малых значений k время выполнения O(knk+1) не особо практично. Например, если n = 1000 и k = 10, на компьютере, выполняющем миллион высокоуровневых команд в секунду, решение о том, существует ли в G вершинное покрытие из k узлов, займет 1024секунд — на несколько порядков больше возраста Вселенной. И это для малого значения k, с которым задача должна быть более разрешимой! Естественно спросить себя, можно ли сделать что-то более практичное в том случае, если k является малой константой.
Из этого мы видим, что неразрешимость задачи о вершинном покрытии реально проявляется только при росте k как функции n. Однако даже для умеренно малых значений k время выполнения O(knk+1) не особо практично. Например, если n = 1000 и k = 10, на компьютере, выполняющем миллион высокоуровневых команд в секунду, решение о том, существует ли в G вершинное покрытие из k узлов, займет 1024секунд — на несколько порядков больше возраста Вселенной. И это для малого значения k, с которым задача должна быть более разрешимой! Естественно спросить себя, можно ли сделать что-то более практичное в том случае, если k является малой константой.
Оказывается, можно разработать гораздо лучший алгоритм с временем выполнения 0(2k ∙ kn). Следует обратить внимание на два обстоятельства. Во-первых, подставляя n = 1000 и k = 10, мы видим, что наш компьютер сможет выполнить алгоритм всего за несколько секунд. Во-вторых, с ростом k время выполнения продолжает стремительно расти — просто экспоненциальная зависимость от k переместилась из экспоненты n в отдельную функцию. С практической точки зрения такое решение выглядит более привлекательно.
Разработка алгоритма
Прежде всего заметим, что если граф имеет малое вершинное покрытие, он не может иметь очень много ребер. Вспомните, что степенью узла графа называется количество инцидентных ему ребер.
(10.1) Если граф G = (V, E) содержит n узлов, максимальная степень любого узла не превышает d и существует вершинное покрытие с размером не более k, то G содержит не более kd ребер.
Доказательство. Пусть S — вершинное покрытие G с размером k' ≤ k. У каждого ребра G по крайней мере один конец принадлежит S; но каждый узел в S может покрывать не более d ребер. Следовательно, в G может быть не более k'd ≤ kd ребер. ■
Так как степень любого узла в графе не превышает n - 1, у (10.1) имеется простое следствие.
(10.2) Если граф G = (V, E) содержит n узлов и вершинное покрытие с размером к, то G содержит не более k(n - 1) ≤ kn ребер.
На первом шаге алгоритма мы можем проверить, содержит ли G более kn ребер; если содержит, то можно утверждать, что ответ на задачу принятия решения — существует ли вершинное покрытие с размером не более k? — отрицателен. После этой проверки будем считать, что G содержит не более kn ребер.
Идея, заложенная в основу алгоритма, концептуально очень проста. Сначала мы рассматриваем любое ребро e = (u, v) в G. В любом k-узловом вершинном покрытии S графа G либо u, либо vпринадлежит S. Предположим, и принадлежит вершинному покрытию S. Если удалить u и все его инцидентные ребра, остальные ребра должны покрываться не более чем k - 1 узлами. Иначе говоря, если G - {u} — граф, полученный удалением и и всех инцидентных ребер, в G - {u} должно существовать вершинное покрытие с размером не более k - 1. Аналогичным образом, если vпринадлежит S, из этого следует, что в G - {v} существует вершинное покрытие с размером не более k - 1.
Ниже приведена конкретная формулировка этой идеи.
(10.3) Пусть e = (u, v) — произвольное ребро G. Граф G имеет вершинное покрытие с размером не более k в том, и только в том случае, если по крайней мере один из графов G - {u} и G - {v} имеет вершинное покрытие с размером не более k - 1.
Доказательство. Сначала предположим, что G имеет вершинное покрытие S с размером не более k. Тогда S содержит по крайней мере один из узлов u или v; предположим, это u. Тогда множество S - {u} должно покрывать все ребра, у которых ни один из концов не равен u. Следовательно, S - {u} является вершинным покрытием с размером не более k - 1 для графа G - {u}.
И наоборот, предположим, что один из графов G - {u} и G - {v} имеет вершинное покрытие с размером не более k - 1, — допустим, G - {u} имеет такое вершинное покрытие T. Тогда множество T U {u} покрывает все ребра в G, поэтому оно является вершинным покрытием для G с размером не более k. ■
Утверждение (10.3) напрямую устанавливает правильность следующего рекурсивного алгоритма для принятия решения о наличии у G вершинного покрытия из k узлов.

Анализ алгоритма
Найдем границу для времени выполнения алгоритма. На интуитивном уровне поиск производится по “дереву возможностей”; рекурсивное выполнение алгоритма можно представить, как рост дерева, в котором каждый узел соответствует отдельному рекурсивному вызову. Дочерними узлами, соответствующими рекурсивному вызову с параметром k, являются два узла, соответствующие рекурсивным вызовам с параметром k - 1. Таким образом, дерево содержит не более 2k+1 узлов. При каждом рекурсивном вызове затраты времени составляют O(kn).
Итак, мы можем доказать следующее утверждение:
(10.4) Время выполнения алгоритма вершинного покрытия для графа из n узлов с параметром k равно O(2k ∙ kn).
Для доказательства можно воспользоваться индукцией. Если обозначить T(n, k) время выполнения для графа из n узлов с параметром k, то T(∙,∙) удовлетворяет следующему рекуррентному отношению для некоторой абсолютной константы с:
![]()
Индукцией по k ≥ 1 легко доказывается, что T(n, к) ≤ с ∙ 2kkn. В самом деле, если это утверждение истинно для k - 1, то
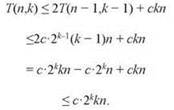
Таким образом, этот алгоритм значительно улучшает простой метод “грубой силы”. Тем не менее ни один экспоненциальный алгоритм не может нормально масштабироваться в течение долгого времени; это относится и к нашему алгоритму. Предположим, мы хотим знать, существует ли вершинное покрытие, содержащее до 40 узлов вместо 10; на той же машине выполнение алгоритма займет много лет.