Алгоритмы - Разработка и применение - 2016 год
Решение NP-сложных задач для деревьев - Расширение пределов разрешимости
В разделе 10.1 мы разработали алгоритм для задачи о вершинном покрытии, который хорошо работает при не слишком большом размере покрытия. Было показано, что найти относительно малое вершинное покрытие намного проще, чем в полностью обобщенной задаче вершинного покрытия.
В этом разделе рассматриваются особые случаи NР-полных задач графов другого типа — не с малым естественным параметром “размера”, но со структурно “простым” входным графом. Вероятно, простейшей разновидностью графа является дерево. Вспомните, что ненаправленный граф называется деревом, если он является связным и не содержит циклов. Дело даже не только в структурной простоте таких деревьев, но и в том, что многие NР-сложные задачи графов эффективно решаются в том случае, если нижележащий граф является деревом. На качественном уровне это объясняется следующим образом: если рассмотреть поддерево входных данных с корнем в некотором узле v, решение задачи, ограничиваемое этим поддеревом, “взаимодействует” с остатком дерева через v. Итак, рассматривая разные варианты расположения v в общем решении, мы фактически можем отделить задачу из поддерева v от задачи из остального дерева.
Чтобы формализовать этот общий подход и преобразовать его в эффективный алгоритм, потребуются определенные усилия. Сейчас вы увидите, как это делается для разновидностей задачи о независимом множестве; однако важно помнить, что этот принцип достаточно общий, и с таким же успехом можно было рассмотреть для деревьев многие другие NР-полные задачи графов.
Сначала мы покажем, что сама задача о независимом множестве для дерева может быть решена жадным алгоритмом. Затем будет рассмотрено обобщение — задача о независимом множестве с максимальным весом, в котором узлам назначаются веса, а ищется независимое множество с максимальным весом. Вы увидите, что задача о независимом множестве с максимальным весом решается для деревьев средствами динамического программирования с использованием довольно прямолинейной реализации описанных выше рассуждений.
Жадный алгоритм для задачи о независимом множестве для деревьев
Наше рассмотрение жадного алгоритма для дерева начнется с анализа того, как решение выглядит с точки зрения одного ребра (разновидность идеи из раздела 10.1). Возьмем ребро е = (u, v) в графе G. В любом независимом множестве S в G не более чем один из узлов и или v может принадлежать S. Нам хотелось бы найти ребро е, для которого жадный алгоритм мог бы решить, какой из двух концов следует включить в независимое множество.
Для этого мы воспользуемся важнейшим свойством деревьев: у каждого дерева должен быть как минимум один лист — узел со степенью 1. Возьмем лист v; пусть (u, v) — уникальное ребро, инцидентное v. Как “жадно” оценить относительные преимущества включения и или v в независимое множество S? Если включить v, то из всех остальных узлов только u напрямую “блокируется” от присоединения к независимому множеству. Если включить u, то блокируется не только v, но и все остальные узлы, присоединенные к u. Итак, если мы стремимся к максимизации размера независимого множества, похоже, включение v должно быть лучше (или по крайней мере не хуже) включения u.
(10.5) Если T = (V, E) — дерево, а v — лист этого дерева, то существует независимое множество максимального размера, содержащее v.
Доказательство. Рассмотрим независимое множество максимального размера S. Пусть е = (u, v) — уникальное ребро, инцидентное узлу v. Очевидно, по крайней мере один из узлов и или vпринадлежит S; в противном случае мы могли бы добавить v в S с увеличением размера. Теперь, если v ∈ S, то работа закончена; а если u ∈ S, то мы можем получить другое независимое множество S' того же размера, удалив u из S и вставив v. ■
Мы можем использовать (10.5) многократно для выявления и удаления узлов, которые могут быть включены в независимое множество. При удалении дерево T может потерять связность. Чтобы избежать лишних проблем, мы опишем алгоритм для более общего случая, при котором используемый граф представляет собой лес — граф, в котором каждая компонента связности представляет собой дерево. Задачу нахождения независимого множества максимального размера для леса можно рассматривать как соответствующую задаче для деревьев: оптимальное решение для леса представляет собой простое объединение оптимальных решений для каждого дерева, и при этом можно использовать (10.5) для анализа задачи в каждом дереве.
Допустим, имеется лес F; тогда (10.5) позволяет принять первое решение по следующему жадному правилу. Снова рассмотрим ребро e = (u, v), где v является листом. В независимое множество S включается узел v и не включается узел u. С этим решением мы можем удалить узел v (так как он уже включен) и узел u (так как он не может быть включен) с получением меньшего леса. Далее выполнение рекурсивно продолжается для уменьшенного леса для получения решения.
Чтобы найти независимое множество максимального размера для леса F:

(10.6) Приведенный алгоритм находит независимое множество максимального размера для лесов (а следовательно, и для деревьев).
Хотя утверждение (10.5) кажется очень простым, в действительности оно представляет применение одного из принципов разработки жадных алгоритмов, приведенных в главе 4: метода замены. В частности, в нашем алгоритме независимого множества центральное место занимает тот факт, что любое решение, не содержащее конкретный лист, может быть “преобразовано” в не худшее решение, содержащее этот лист.
Чтобы реализовать этот алгоритм для быстрого выполнения, необходимо хранить текущий лес F так, чтобы способ хранения обеспечивал эффективное нахождение ребра, инцидентного листу. Реализовать этот алгоритм с линейным временем несложно: лес должен храниться так, чтобы это можно было сделать за одну итерацию цикла Пока за время, пропорциональное количеству удаляемых ребер при исключении u и v.
Жадный алгоритм для более общих графов
Работоспособность жадного алгоритма, приведенного выше, для общих графов не гарантирована, потому что не гарантируется нахождение листа при каждой итерации. Однако утверждение (10.5) относится к любому графу: если имеется произвольный граф G с ребром (u, v), в котором и является единственным соседом v, то всегда безопасно поместить v в независимое множество, удалить u и v и повторить с уменьшенным графом.
Итак, если многократное удаление узлов со степенью 1 и их соседей позволит исключить весь граф, мы гарантированно находим независимое множество с максимальным размером — даже если исходный граф не был деревом. А если исключить весь граф не удастся, возможно, мы последовательно выполним несколько итераций алгоритма, отчего размер графа уменьшится, а другие методы станут более приемлемыми. Таким образом, жадный алгоритм является полезной эвристикой, которую можно с пользой применить к произвольному графу для продвижения к цели нахождения большого независимого множества.
Независимое множество с максимальным весом для деревьев
Теперь обратимся к более сложной задаче — нахождению независимого множества с максимальным весом. Как и прежде, предполагается, что граф представляет собой дерево T = (V, E), но теперь с каждым узлом связывается положительный вес wv. Задача нахождения независимого множества с максимальным весом заключается в нахождении в графе Т= (V, Е) такого независимого множества S, что общий вес ![]()
Сначала мы опробуем идею, которая использовалась ранее для построения жадного решения в случае без весов. Рассмотрим ребро e = (u, v), для которого v является листом. Включение vблокирует вхождение в независимое множество меньшего числа узлов; следовательно, если вес v хотя бы не меньше веса u, мы можем принять жадное решение, как это делалось в случае без весов. Однако если wv < wu, мы сталкиваемся с дилеммой: включение и обеспечивает больший вес, но включение v оставляет больше вариантов на будущее. Похоже, простого способа принять решение локально, без учета оставшейся части графа, не существует. Впрочем, кое-что сказать все же можно. Если узел u имеет много соседей v1, v2, ..., которые являются листьями, это же решение следует принять для всех: принимая решение о том, что u не включается в независимое множество, мы с таким же успехом можем включить все соседние листья. Таким образом, для поддерева, состоящего из u и соседних листьев, стоит рассматривать только два “разумных” решения: включать и или включать все листья.
Эти идеи будут использоваться для разработки алгоритма с полиномиальным временем средствами динамического программирования. Как вы помните, динамическое программирование позволяет сформировать несколько разных решений, которые строятся через последовательность подзадач, и только в конце решить, какие из этих возможностей будут использоваться в общем решении.
Первое решение, которое следует принять для алгоритма динамического программирования, — выбор подзадач. Для независимого множества с максимальным весом подзадачи будут строиться размещением корня дерева T в произвольном узле r; вспомните, что это операция “ориентирует” все ребра дерева в направлении от r. А именно: для каждого узла u ≠ r родителем р(u) узла и является узел, смежный с u на пути от корня r. Другими соседями u становятся его дочерние узлы; для обозначения множества дочерних узлов u будет использоваться запись children(u). Узел uи все его потомки образуют поддерево Tu, корнем которого является u.
Наши подзадачи будут базироваться на этих поддеревьях Тu. Дерево Tr соответствует исходной задаче. Если u ≠ r является листом, то Тu состоит из одного узла. Для узла u, все дочерние узлы которого являются листьями, Тu является как раз таким поддеревом, о котором говорилось выше.
Чтобы решить эту проблему средствами динамического программирования, мы начнем с листьев и постепенно будем двигаться вверх по дереву. Для узла u подзадача, связанная с деревом Тu, решается после решения подзадач всех его дочерних узлов. Чтобы получить независимое множество с максимальным весом S для дерева Тu, рассмотрим два случая: узел u либо включается в S, либо не включается. Если узел u включается, то мы не сможем включить его дочерние узлы; если же u не включается, то дочерние узлы могут включаться, а могут u не включаться. Это наводит на мысль о том, что для каждого поддерева Тu должны определяться две подзадачи: подзадача 0РТin(u) для максимального веса независимого множества Тu, включающего u, и подзадача 0РТout(u) для максимального веса независимого множества Тu, не включающего u.
После того как подзадачи будут выбраны, легко понять, как происходит рекурсивное вычисление этих значений. Для листа u ≠ r имеем 0РТout(u) = 0 и 0РТin(u) = wu. Для всех остальных узлов u действует следующее рекуррентное отношение, определяющее 0РТout(u) и 0РТin(u) с использованием значений дочерних узлов u.
(10.7) Для узла u, имеющего дочерние узлы, следующее рекуррентное отношение определяет значения подзадач:

Используя это рекуррентное отношение, мы получаем алгоритм динамического программирования, основанный на построении оптимальных решений по поддеревьям все большего и большего размера. Массивы Мout[u] и Мin[u] используются для хранения значений 0РТout(u) и 0РТin(u) соответственно. Чтобы построить решения, необходимо обработать все дочерние узлы некоторого узла, прежде чем обрабатывать сам узел; в терминологии обхода дерева узлы посещаются в обратном порядке (post-order).

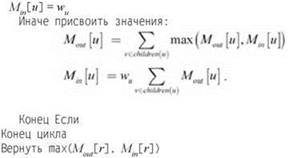
Так мы получаем значение независимого множества с максимальным весом. Теперь, по стандартной практике алгоритмов динамического программирования, которая уже встречалась ранее, можно легко восстановить само независимое множество с максимальным весом; для этого мы сохраняем решение, принятое для каждого узла, а потом посредством обратного отслеживания по этим решениям определяем, какие узлы следует включить в множество.
(10.8) Приведенный выше алгоритм находит независимое множество с максимальным весом для деревьев за линейное время.